Zookeeper
![]()
ZooKeeper 是一个分布式的,开放源码的分布式应用程序协调服务,是 Hadoop 和 Hbase 的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
一、Zookeeper基础
1.1 使用场景
- 分布式协调组件:通过 watch 机制可以协调好节点之间的数据一致性
- 分布式锁:通过分布式锁可以做到强一致性
- 无状态化实现
- 负载均衡
- 数据发布/订阅
- 命名服务
1.2 部署
docker-compose.yaml
1 | version: '3.8' |
zoo.cfg
1 | dataDir=/data |
1.3 基本命令
- 启动|关闭|查看状态
1 | zkServer.sh start|stop|status |
- 进入 zk
1 | zkCli.sh |
- 查看内部数据结构
1 | ls [path] |
二、内部数据结构
2.1 是如何存储数据的
Zookeeper 中的数据是保存在节点上的,即 znode,多个 znode 就构成一个树的结构。
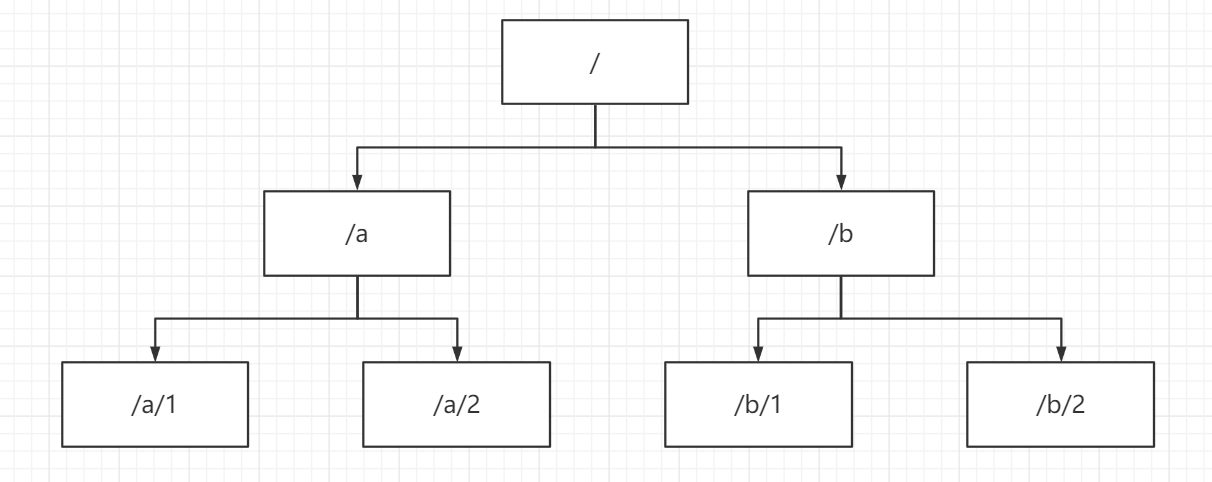
如图,a 和 b 就是 Zookeeper 的 znode,创建 znode 方式如下
1 | create /[znode_name] |
2.2 znode结构
Zookeeper 中的 zonode,包含以下几个部分:
- data:保存数据
- acl:权限
- c:创建权限
- w:写权限
- r:读权限
- d:删除权限
- a:admin 管理者权限
- stat:描述当前 znode 的元数据
- child:当前节点的子节点
1 | 查看znode详细信息 |
2.3 znode类型
- 持久节点:在会话结束后仍会存在
- 持久序号节点:根据先后顺序,会在结点之后带上一个数值,适用于分布式锁的场景(单调递增)
- 临时节点:会话结束后会自动删除,适用于注册与服务发现的场景
- 临时序号节点:跟持久序号节点相同,适用于分布式锁的场景
- 容器节点:当容器节点中没有任何子节点时,该容器节点会被定期删除(60s)
- TTL 节点:可以指定节点的到期时间
持久序号节点创建
1 | create -s /[znode_name] |
临时节点创建
1 | create -e /[znode_name] |
临时序号节点创建
1 | create -e -s /[znode_name] |
容器节点创建
1 | create -c /[znode_name] |
TTL 节点创建
1 | 通过系统配置开启 |
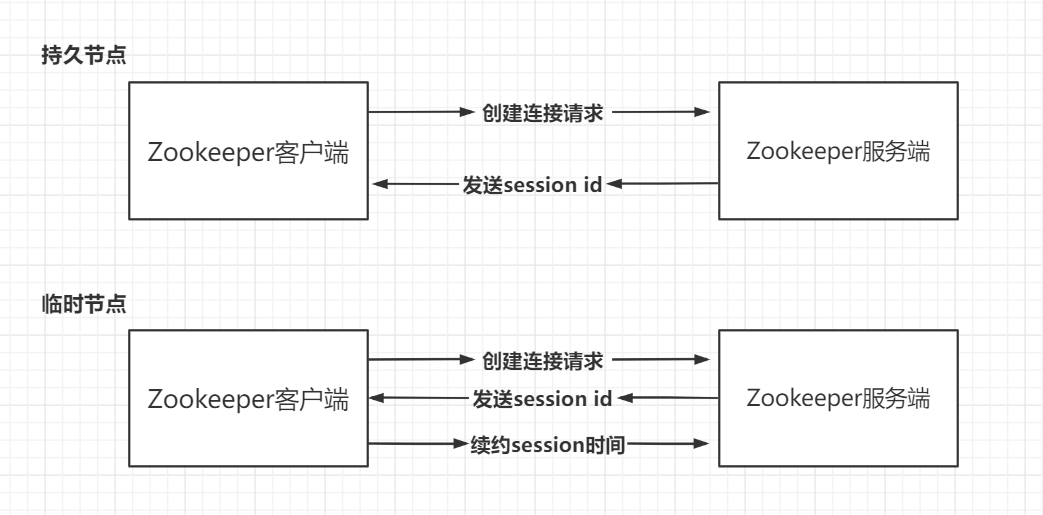
持久节点
持久节点在创建后服务端会发送一个 session id,并一直保留着。
临时节点
临时节点在创建时后服务器也会发送一个 session id,在会话持续的过程中客户端会不断向服务端续约 session id 的时间,当客户端没有继续续约,而服务端内部的计时器到期时,就会将该 session id 所对应的 znode 全部删除。
2.4 持久化机制
Zookeeper 的数据是运行在内存中的,所以提供了两种持久化机制:
- 事务日志:Zookeeper 将执行过的命令以日志的形式存储在 dataLogDir / dataDir 中,类似于 redis 的 AOF
- 数据快照:在一定时间间隔内做一次数据快照,存储在快照文件中(snapshot),类似于 redis 的RDB
Zookeeper 通过这两种持久化机制,在恢复数据时先将快照文件中的数据恢复到内存中,再用日志文件中的数据做增量恢复,可以实现高效的持久化。
三、zkCli的使用
- 递归查询
1 | ls -R /[znode_name] |
- 删除节点
1 | deleteall /[znode_name] |
- 乐观锁删除
1 | delete -v [version] /[znode_name] |
- 给当前会话注册用户,并创建节点赋予该用户权限
1 | addauth digest [user]:[password] |
四、分布式锁
在分布式的环境下,如果在一个节点去上了个锁,当请求被负载均衡分配到了其它节点,那么锁就无法形成互斥,所以节点之间使用 Zookeeper,做一个协调中心,将锁上传到 Zookeeper,其它节点要用到就去 Zookeeper 拿这个锁,这就是分布式锁。
Zookeeper 锁的分类:
- 读锁:大家都可以读,前提是之前没有写锁。(读锁比喻成约会,大家都有机会和女神约会,约会前提是女神没结婚)
- 写锁:只有写锁才能写,前提是不能有任何锁。(写锁比喻成结婚,结婚后只有老公能和女神约会,结婚前提是女神和其他人的关系断干净了)
4.1 上读锁
- 创建一个临时序号节点,节点数据是 read,表示为读锁
- 获取当前 Zookeeper 中序号比自己小的所有节点
- 判断最小节点是否为读锁:
- 如果是读锁:则上锁失败,因为如果最小节点是读锁,那么后面就不可能有写锁,接着为最小节点设置监听,Zookeeper 的 watch 机制会在最小节点发生变化时通知当前节点,再进行后面的步骤,被称为阻塞等待
- 如果不是读锁:则上锁成功
4.2 上写锁
- 创建一个临时序号节点,节点数据是 write,表示为写锁
- 获取 Zookeeper 中的所有节点
- 判断自己是否为最小节点:
- 如果是:上锁成功
- 如果不是:说明前面还有锁,所以上锁失败,接着监听最小节点,如果最小节点发生变化,则重新进行第二步
羊群效应
假设有一百个请求都是要去写锁,那么就会有一百个请求去监听最小节点,那么 Zookeeper 的压力就会非常大,解决方法是将这一百个请求按请求顺序排列,后一个请求去监听前一个请求即可,实现链式监听。
4.3 watch机制
Zookeeper 的 watch 可以看作是一个触发器,当监控的 znode 发生改变,就会触发 znode 上注册的对应事件,请求 watch 的客户端就会接收到异步通知。
zkCli.sh 中使用 watch
1 | create /test |
五、集群部署
Zookeeper 的集群角色有三个:
- Leader:处理集群所有事务的请求,集群只有一个 Leader
- Follower:只处理读请求,参与 Leader 选举
- Observer:只处理读请求,提升集群的性能,但不能参与 Leader 选举
docker-compose.yaml
1 | version: '3.8' |
通过命令查看节点角色
1 | zkServer.sh status |
连接集群
1 | zkCli.sh -server zk01:2181,zk02:2181,zk03:2181 |
5.1 ZAB协议
ZAB(Zookeeper Atomic Broadcast)即 Zookeeper 原子广播协议,通过这个协议解决了集群数据一致性和崩溃恢复的问题。
ZAB 协议中节点的四种状态
- Looking:选举状态
- Following
- Leading
- Observing
初始化集群时 leader 的选举
- 当集群中两台节点启动时,就会开始 leader 的选举,选票的格式为
(myid,zXid) - 第一轮投票时,每个节点会生成自己的选票,即自己的
(myid,zXid),然后将选票给到对方,这时候每个节点就会有两张选票,即自己的和对方节点的 - 接着就会比较两张选票的
zXid,如果都相同就对比myid,将大的一票投到投票箱中 - 第二轮投票时,每个节点会将上一轮投出去的选票给到其它节点,然后再对比
(myid,zXid),将大的一票投出去,就能够选出 leader - 后来新启动的节点会发现已经有 leader了,就不用做选举的过程了
- 可以看出初始化集群时,leader 的选举主要看
myid
崩溃恢复时的 leader 选举
在 leader 确定了之后,leader 会周期性地向 follower 发送心跳包,当 follower 没有收到 leader 发送过来的心跳包,就会进入选举过程,这时候集群不能对外提供服务。
- 当 leader 挂了之后,follower 的状态会变成 looking
- 接着就进行选举投票,过程和初始化集群时一样
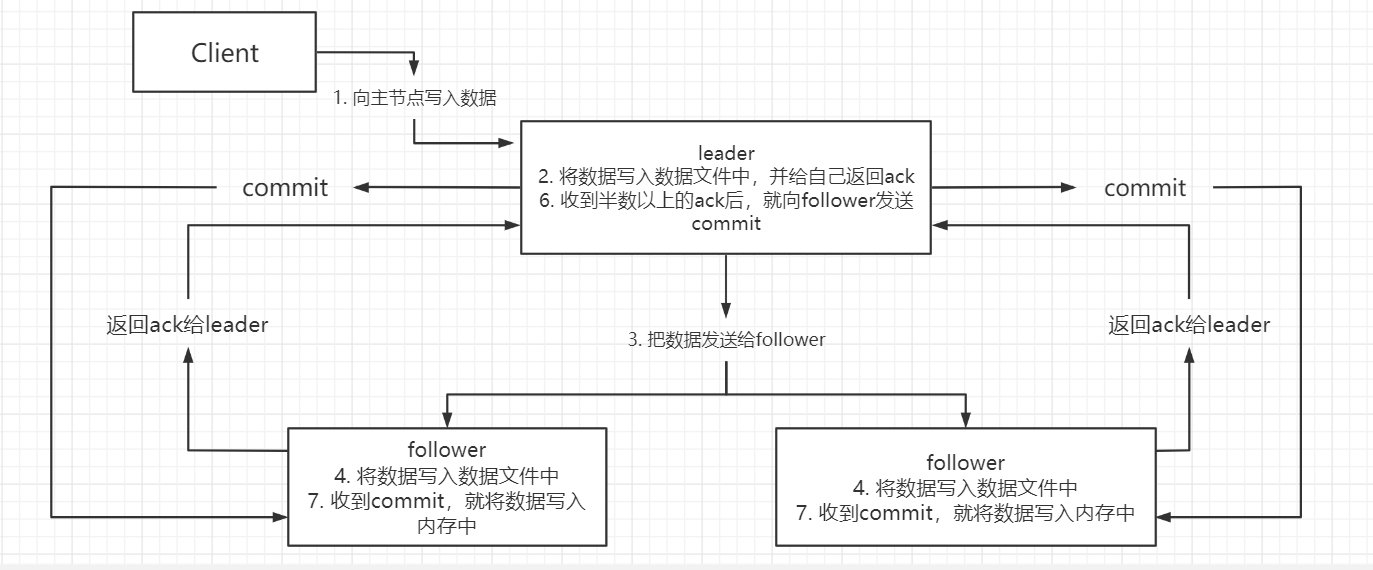
5.2 主从同步原理
5.3 NIO和BIO
NIO
用于被客户端连接的 2181 端口,使用的就是 NIO 的连接模式;客户端开启 watch 时,使用的也是 NIO。
BIO
集群在进行选举时,多个节点之间的通信端口,使用的是 BIO 的连接模式。
install_url to use ShareThis. Please set it in _config.yml.