记录一次ipv4_forward被修改导致的生产事故
生产集群的节点内核模块被异常修改,导致集群服务与服务之间网络通信异常,产生了较大规模的生产事故。
此次事故涉及到两个主要的内核模块被修改:
- net.ipv4.ip_forward: 用于启用 IP 转发,当此模块加载时,Linux 内核会允许将数据包转发到其他网络
尝试复现
在一个集群中启用两个 Pod,通过这两个 Pod 模拟业务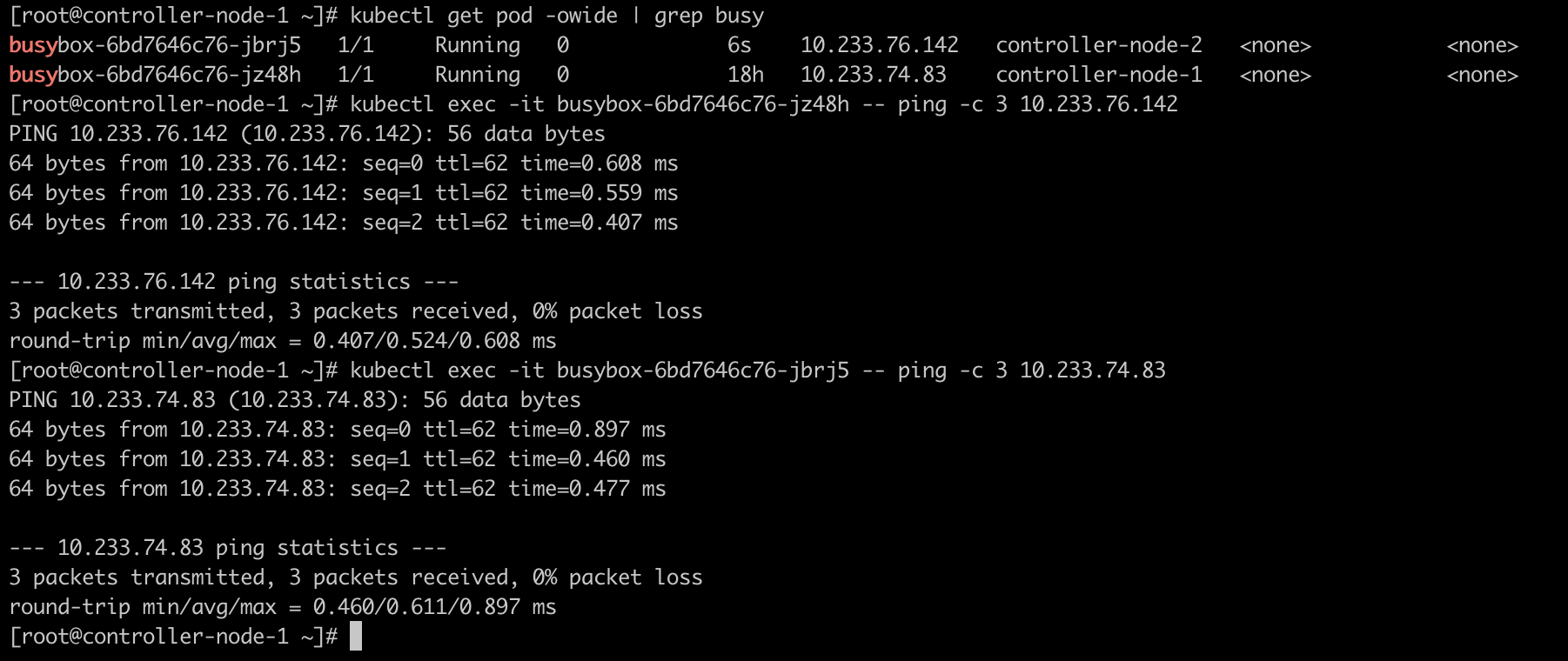
修改 controller-node-2 节点的 /etc/sysctl.d/99-sysctl.conf 文件,并加载(sysctl -p)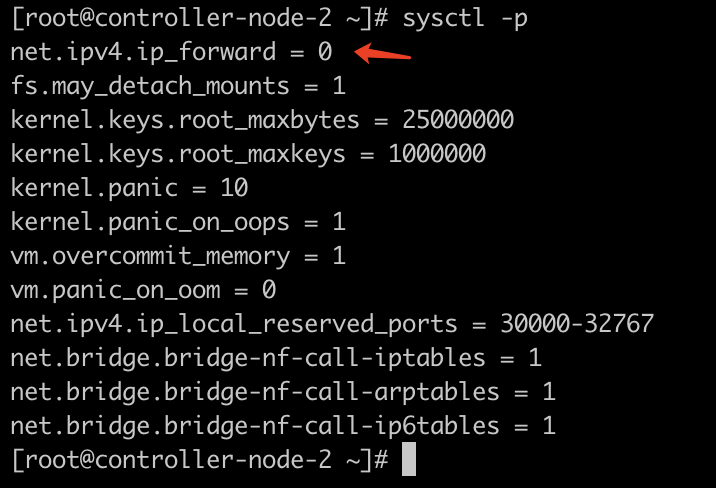
1 | net.ipv4.ip_forward=0 |
此时再去测试连通性,已经不通了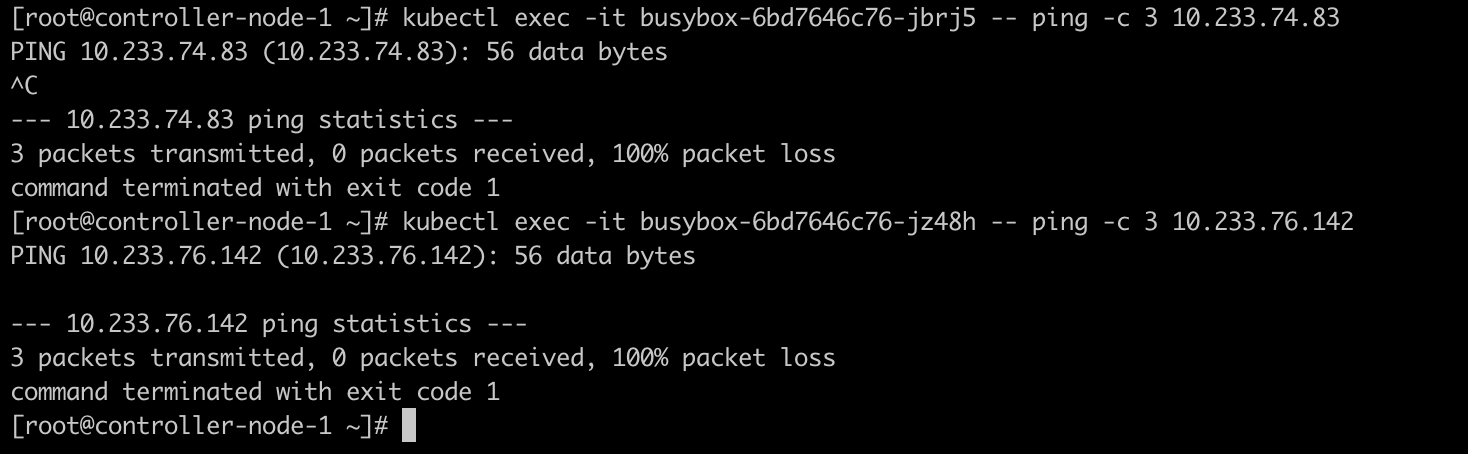
尽管是在同一个宿主机上的 Pod,也无法进行通信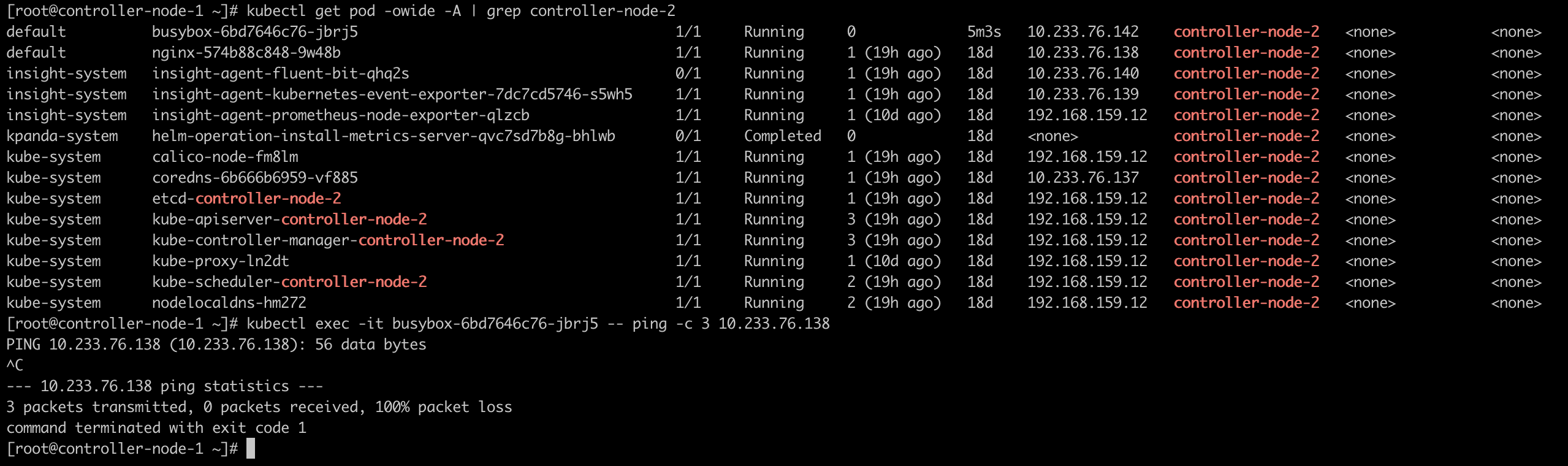
节点之间能够正常通信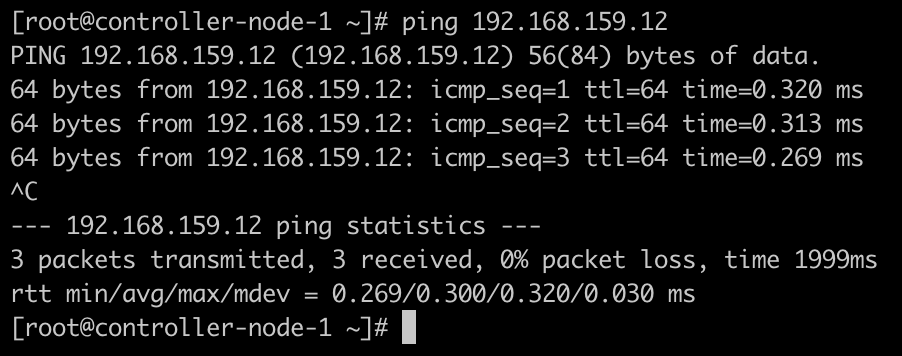
查看 calico 组网状态,显示正常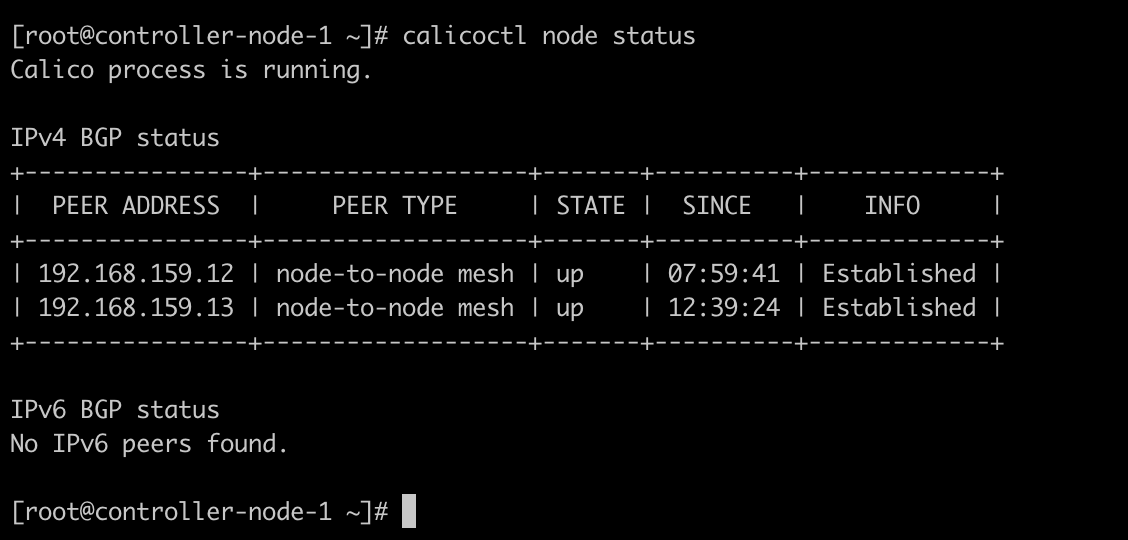
通过正常节点的 Pod 去 ping 异常节点的 Pod,正常节点抓包,发现没有回包
1 | [root@controller-node-1 ~]# tcpdump -i any host 10.233.74.83 or 10.233.76.142 -nnvvv |
异常节点抓包,发现 icmp 包有到达该节点上,但目标地址没有进行响应,说明流量没有抵达目的地 Pod
1 | [root@controller-node-2 ~]# tcpdump -i any host 10.233.74.83 or 10.233.76.142 -nnvvv |
通过异常节点的 Pod 去 ping 正常节点的 Pod,正常节点抓包,发现没有任何包,说明流量没有从异常节点转发出来
1 | [root@controller-node-1 ~]# tcpdump -i any host 10.233.74.83 or 10.233.76.142 -nnvvv |
异常节点,进入 Pod 对应的网络命名空间进行抓包,可以看到有 icmp 的请求包,但依旧没有收到响应
1 | [root@controller-node-2 ~]# nsenter -n -t 23056 |
尝试重启该节点的 calico-node,内核模块会被 calico-node 修改回来,此时网络恢复,但 /etc/sysctl.d/99-sysctl.conf 中的 net.ipv4.ip_forward 还是 0,所以在下次重新加载(sysctl -p)的时候,仍然会被设置为关闭状态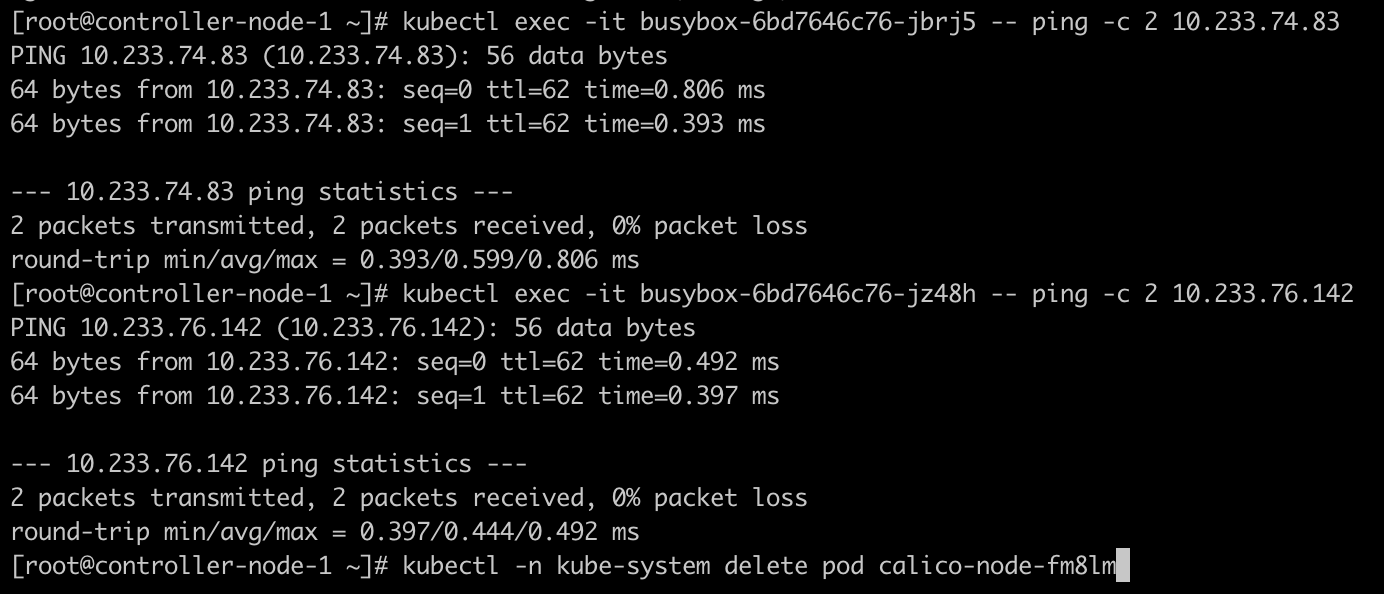

事故总结
此次事故的排障思路是:
- 通过两个在不同宿主机的 Pod,测试跨节点的连通性,不通
- 测试节点之间的连通性,能够正常通信
- 在这两个宿主机进行同一宿主机不同 Pod 的连通性测试,一台通,一台不通 – 确定问题节点
- 通过
calicoctl node status查看组网状态,显示正常 – 暂且排除是 calico 的问题 - 通过 tcpdump 进行抓包,获取正常节点 Pod 到异常节点 Pod 的数据包 – icmp 数据包能够到达异常节点,但异常节点的 Pod 没有响应
- 通过 tcpdump 进行抓包,获取异常节点 Pod 到正常节点 Pod 的数据包 – 异常节点宿主机层面无法获取 icmp 包,通过 nsenter 进入 Pod 的网络命名空间发现,icmp 有发出但无响应,且 icmp 数据包无法到达正常节点,正常节点抓包观察没有任何包
- 尝试重启异常节点 calico-node,网络恢复 – calico-node 启动会修改内核参数,但不会持久化到
/etc/sysctl.d/99-sysctl.conf中 - 查看
/etc/sysctl.d/99-sysctl.conf发现net.ipv4.ip_forward被设置为了0 - 通过 ansible 检查所有节点的
/etc/sysctl.d/99-sysctl.conf文件
记录一次ipv4_forward被修改导致的生产事故
https://warnerchen.github.io/2024/03/31/记录一次ipv4-forward被修改导致的生产事故/
You need to set
install_url to use ShareThis. Please set it in _config.yml.