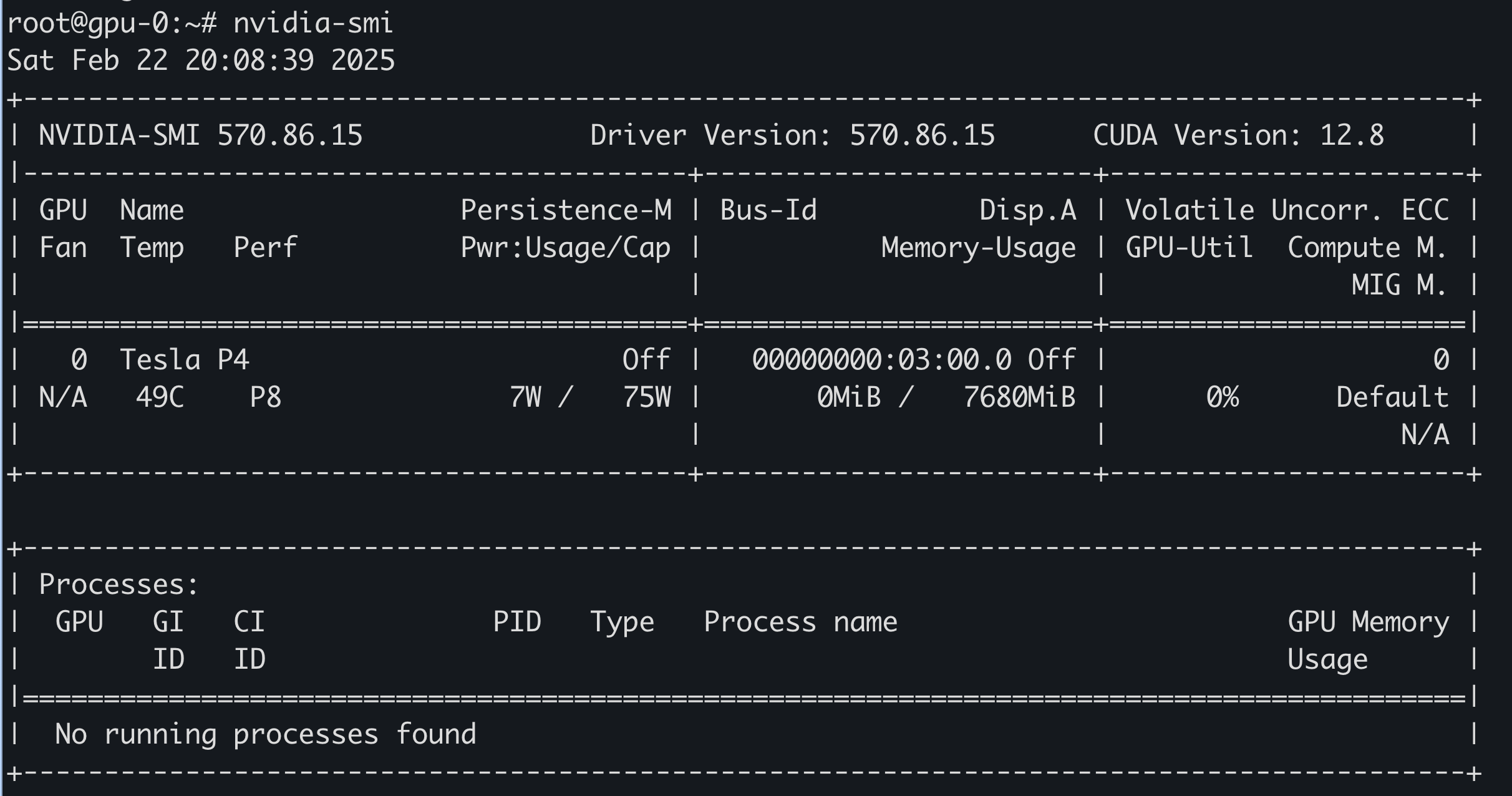
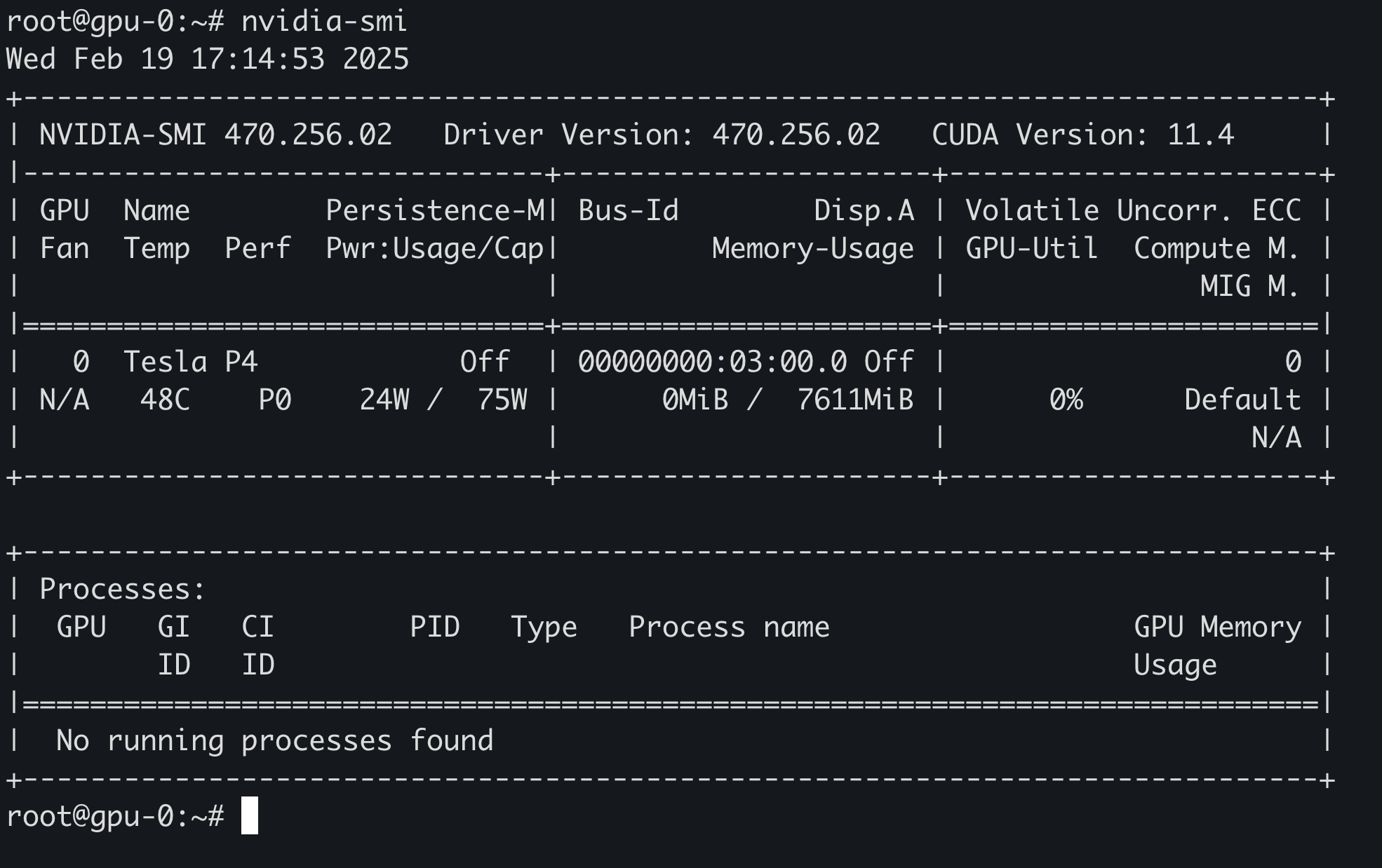
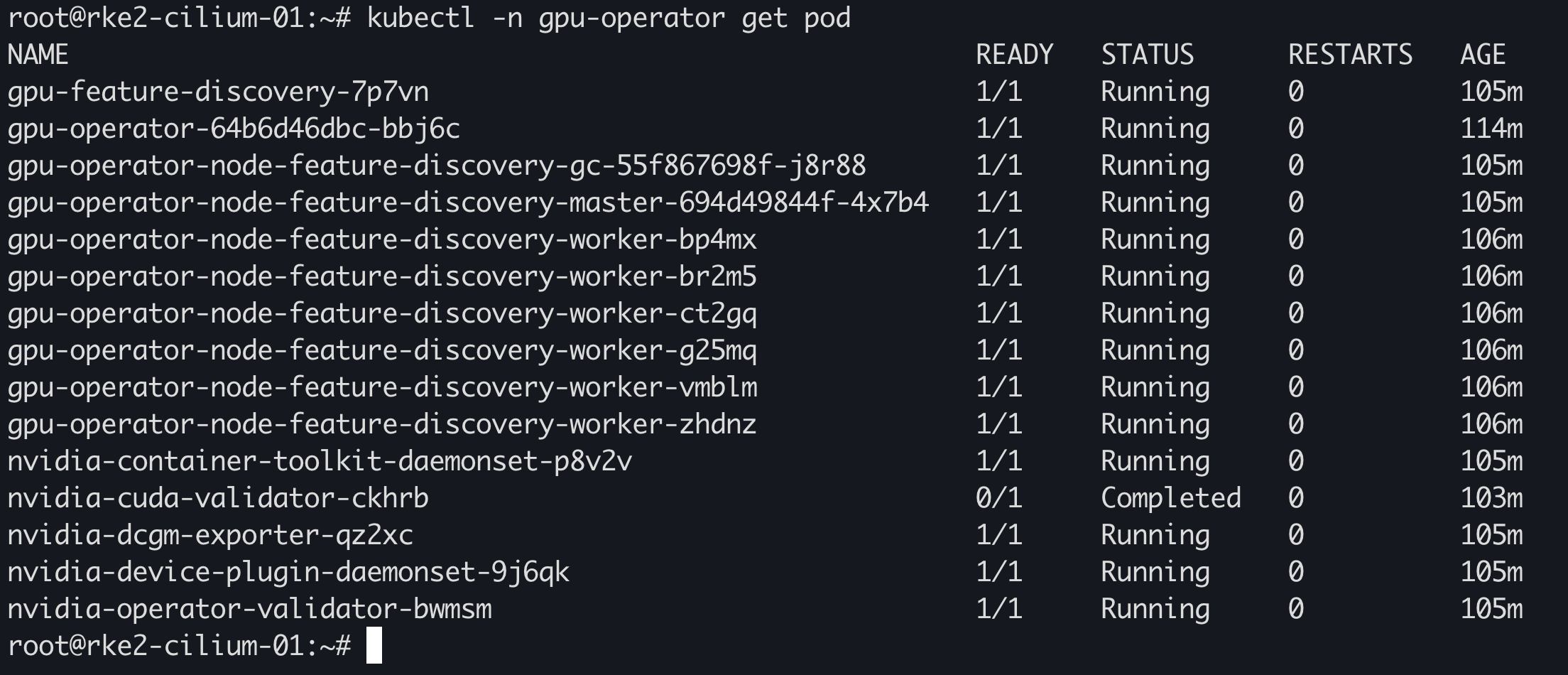
如果执行 nvidia-smi 是 No devices were found or NVIDIA-SMI has failed because it couldn't communicate with the NVIDIA driver. Make sure that the latest NVIDIA driver is installed and running.,可以尝试用下面的命令解决:
root@gpu-0:~# docker run --rm --runtime=nvidia --gpus all harbor.warnerchen.com/library/ubuntu:latest nvidia-smi Wed Feb 19 09:43:47 2025 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 470.256.02 Driver Version: 470.256.02 CUDA Version: 11.4 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla P4 Off | 00000000:03:00.0 Off | 0 | | N/A 49C P0 23W / 75W | 0MiB / 7611MiB | 2% Default | | | | N/A | +-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+
root@rke2-cilium-01:~# kubectl logs nbody-gpu-benchmark Run "nbody -benchmark [-numbodies=<numBodies>]" to measure performance. -fullscreen (run n-body simulation in fullscreen mode) -fp64 (use double precision floating point values for simulation) -hostmem (stores simulation data in host memory) -benchmark (run benchmark to measure performance) -numbodies=<N> (number of bodies (>= 1) to run in simulation) -device=<d> (where d=0,1,2.... for the CUDA device to use) -numdevices=<i> (where i=(number of CUDA devices > 0) to use for simulation) -compare (compares simulation results running once on the default GPU and once on the CPU) -cpu (run n-body simulation on the CPU) -tipsy=<file.bin> (load a tipsy model file for simulation)
NOTE: The CUDA Samples are not meant for performance measurements. Results may vary when GPU Boost is enabled.
> Windowed mode > Simulation data stored in video memory > Single precision floating point simulation > 1 Devices used for simulation GPU Device 0: "Pascal" with compute capability 6.1
> Compute 6.1 CUDA device: [Tesla P4] 20480 bodies, total timefor 10 iterations: 27.727 ms = 151.272 billion interactions per second = 3025.446 single-precision GFLOP/s at 20 flops per interaction