Rancher Pod Metrics 部分 Panel No data 问题排查
Rancher Pod Metrics 有部分 Panel 显示 No data,只有 Memory Utilization 显示正常:
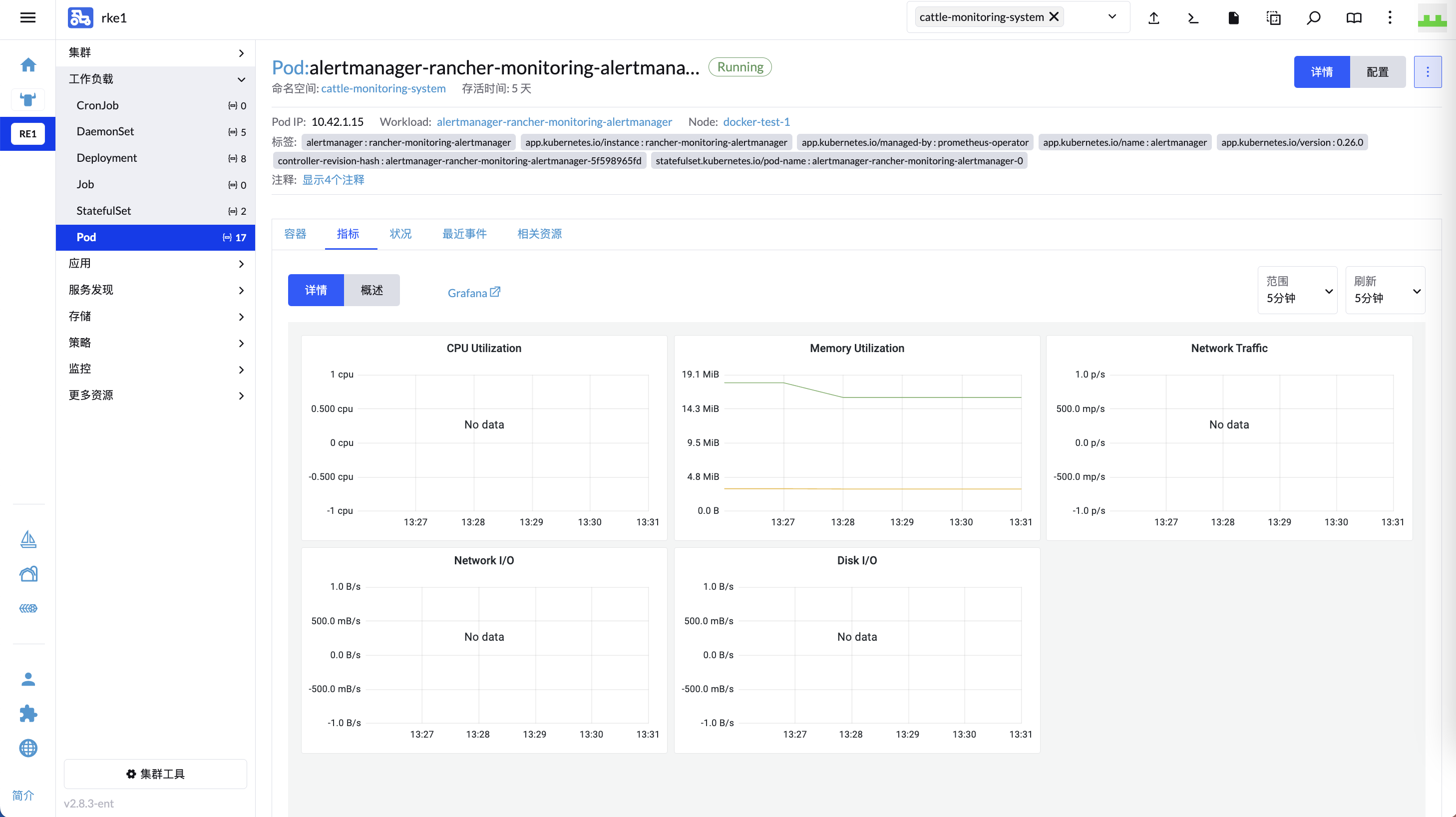
Rancher Pod Metrics 部分 Panel No data 问题排查
Rancher Pod Metrics 有部分 Panel 显示 No data,只有 Memory Utilization 显示正常:
NeuVector 有一个名为 nvprotect 的内部保护机制,用于限制用户对 NeuVector pod 的访问权限。
例如 sh、ls 等命令是无法使用的:

如果需要关闭,可以通过接口进行关闭,此处提供脚本,支持关闭 Controller、Scanner、Enforcer 的 nvprotect。
部署 ECK Operator:
1 | kubectl create -f https://download.elastic.co/downloads/eck/2.16.1/crds.yaml |
Harvester 是 SUSE 的一款开源 HCI 解决方案,基于 Kubernetes 的现代化 HCI 平台,旨在简化虚拟化管理,同时与云原生技术无缝集成。
Harvester 安装且对接 Rancher 后,就可以直接在 Rancher 进行虚拟机的创建/删除等动作。
基于 OT-CONTAINER-KIT/redis-operator 项目,使用 Operator 在 Kubernetes 上部署 Redis。