NeuVector 通过 Response Rules 抑制告警
NeuVector 默认内置了一些网络规则。当这些规则被命中并触发告警时,某些告警可能不会提供 Review Rule 按钮用于直接加白。如果该告警属于误报(即应用的正常行为),就可能持续产生大量告警,从而造成告警噪音。

NeuVector 通过 Response Rules 抑制告警
NeuVector 默认内置了一些网络规则。当这些规则被命中并触发告警时,某些告警可能不会提供 Review Rule 按钮用于直接加白。如果该告警属于误报(即应用的正常行为),就可能持续产生大量告警,从而造成告警噪音。
Rancher Elemental 升级报错 error calling index: index of untyped nil
通过 Rancher UI 升级 Elemental 的时候(Helm Upgrade),出现如下报错:

删除手动创建的 Channel,就能正常完成升级。
prof 文件能够用于性能分析,如果 NeuVector 组件出现性能问题(如 CPU 使用率异常高等),可以通过如下方式获取。
在 CI/CD 流水线中,通常会通过 Jenkins 插件等方式触发 NeuVector 的镜像扫描。扫描完成后,可以在 NeuVector UI 页面中确认扫描结果已成功写入系统。
由于镜像扫描本身会消耗一定的时间和资源(尤其是镜像体积较大时,扫描耗时会明显增加),因此在流水线中往往希望在镜像已经完成扫描的情况下避免重复触发扫描任务,以提升整体执行效率。
NeuVector 的 Zero-drift 与 Basic 模式
NeuVector 提供 Zero-drift 和 Basic 两种运行模式,其中 Zero-drift 模式为默认模式。本文基于 NeuVector v5.4.8 版本,通过实际测试对比两种模式在不同 Group 状态(Discover / Monitor / Protect)下的行为差异。
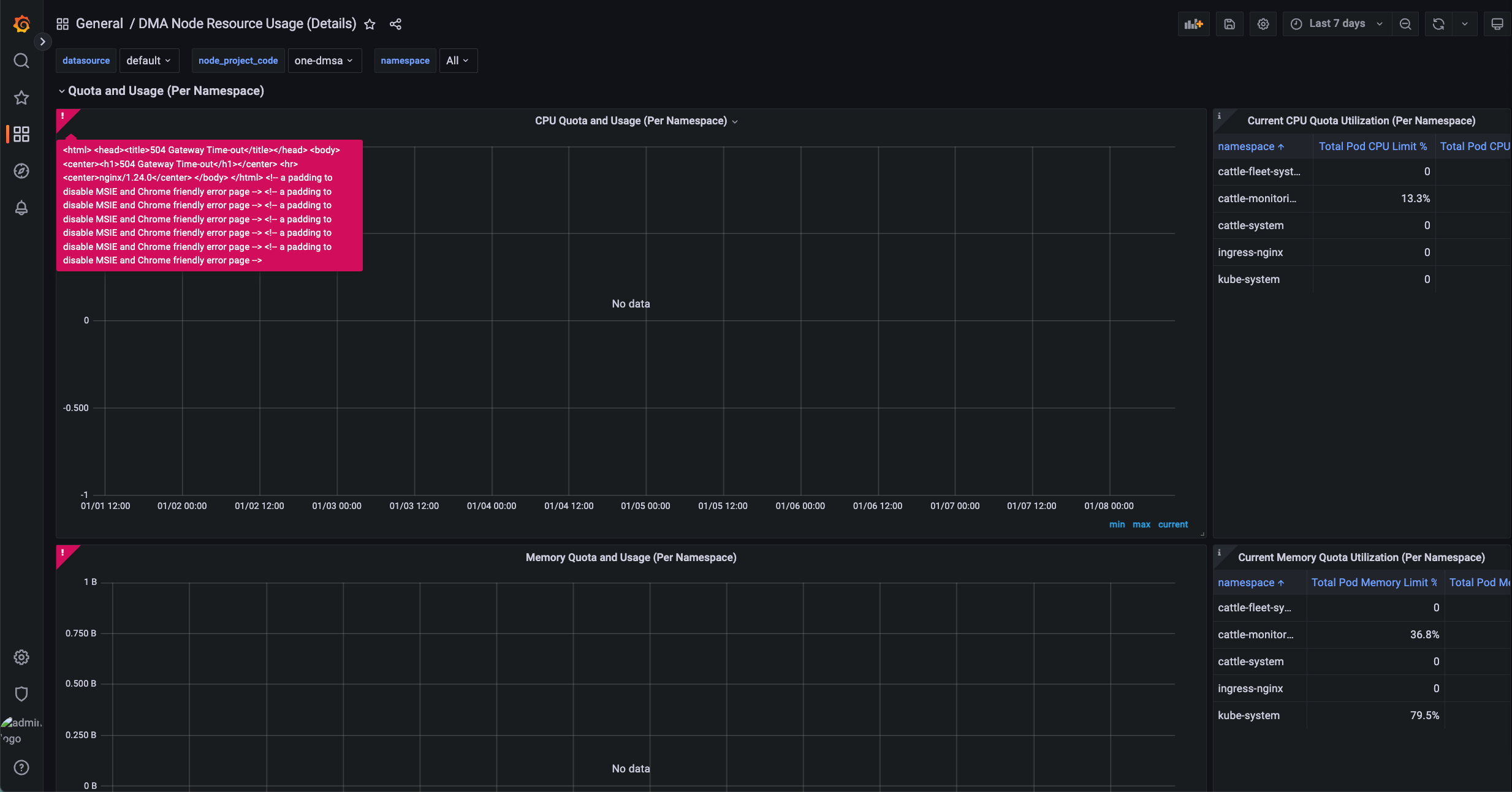
Rancher Monitoring Grafana 出现 504 错误
Rancher Monitoring V2 中,Grafana 通过 Nginx 作为反向代理(grafana-proxy)访问 Prometheus。当 Grafana 执行 PromQL 查询且返回数据量较大(例如查询时间范围较长)时,Prometheus 可能无法在 Nginx 的超时时间内完成响应,从而导致 Grafana 返回 504 Gateway Timeout 错误:
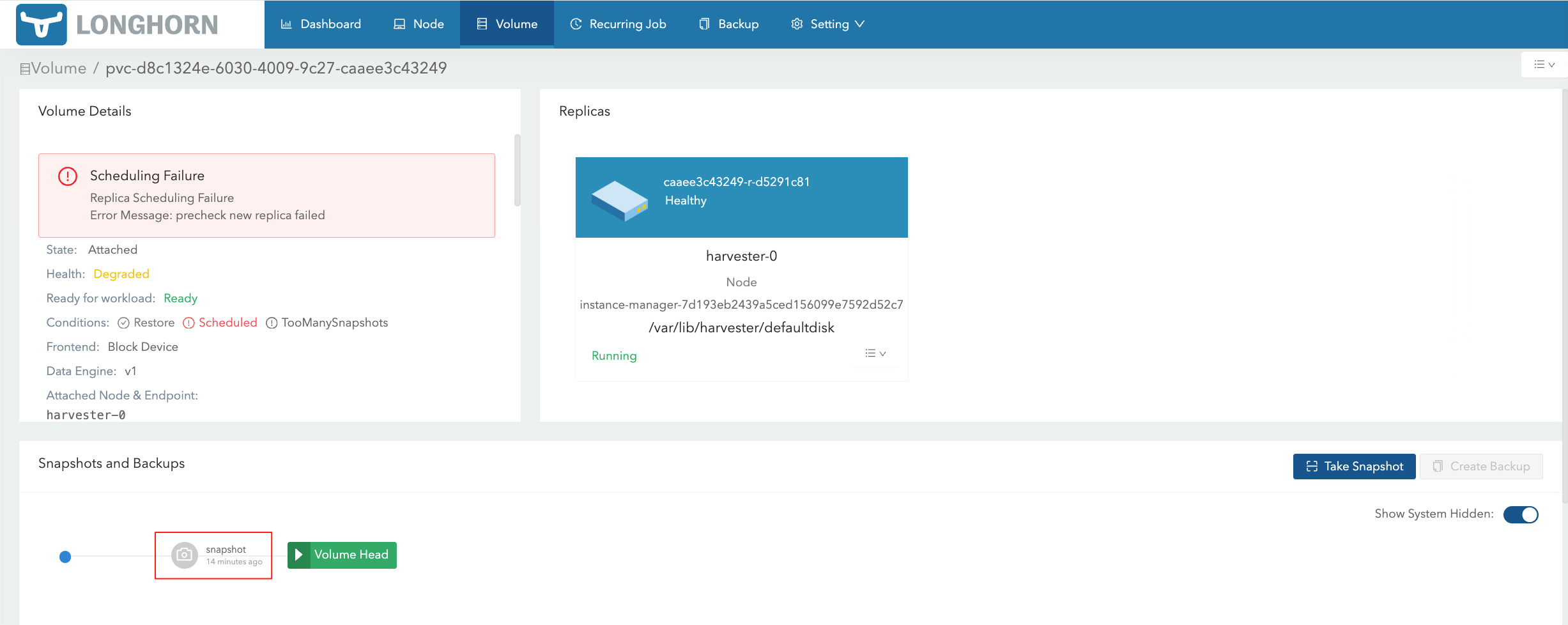
在 HV 将对应的 VM Snapshot 删除后,在 LH 界面仍然能够看到对应的 Volume Snapshot:
Harbor 对接 NeuVector Registry Adapter
Harbor 本身支持对存放的制品进行安全扫描,但需要额外部署扫描器。NeuVector 提供了 Registry Adapter 功能,可与 Harbor 对接以实现扫描能力。
如果通过 Rancher UI 误删除了下游 RKE2 集群节点,最简单的恢复方式是重新注册节点;若涉及节点数量较多且需要快速恢复,可通过恢复 local 集群和下游 RKE2 集群的 ETCD 快照来完成恢复。
需要注意的是,仅恢复下游 RKE2 集群的 ETCD 快照是不够的。对于 Custom 类型的 RKE2 集群,每个节点在 local 集群中都对应有 Machine 等资源,因此需要一并考虑恢复。
此方法需要确保 local 集群和下游 RKE2 集群都有删除操作前的 ETCD 快照备份。
默认情况下,Longhorn 使用 Kubernetes 集群的默认 CNI 网络,这个网络会被整个集群中的其他工作负载共享,并且通常只涉及单个网络接口。
如果需要隔离 Longhorn 的集群内部数据流量(出于安全或性能考虑),Longhorn 支持通过 Storage Network 设置来实现这一点。