使用 LlamaFactory 进行模型微调
模型微调(Fine-tuning) 是指在一个已经训练好的大模型基础上,用特定领域或特定任务的数据继续训练,使模型在某类问题上表现得更好。
开源工具 LlamaFactory 可以轻松地对模型进行微调:https://github.com/hiyouga/LlamaFactory
部署 LlamaFactory
此处使用 Docker 基于 NVIDIA GPU 设备部署 LlamaFactory。
GPU 节点需要安装好 Nvidia 驱动,参考文档:https://warnerchen.github.io/2024/12/17/RKE-RKE2-%E8%8A%82%E7%82%B9%E9%85%8D%E7%BD%AE-Nvidia-Container-Toolkit/#GPU-%E8%8A%82%E7%82%B9%E5%AE%89%E8%A3%85-Nvidia-%E9%A9%B1%E5%8A%A8
1 | root@gpu-0:~# nvidia-smi |
驱动安装完成后,安装 Docker 和 Nvidia Container Runtime,安装方法参考官方文档:
- https://docs.docker.com/engine/install/
- https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html
1 | root@gpu-0:~# docker info |
验证容器是否可以使用 Nvidia 设备:
1 | docker run --rm --gpus=all nvidia/cuda:12.4.0-base-ubuntu22.04 nvidia-smi |
部署 LlamaFactory:
1 | docker run --rm -it --name llamafactory --gpus=all --ipc=host -p 7860:7860 -p 8000:8000 hiyouga/llamafactory:latest |
随后在容器内执行如下命令开启 Web UI:
1 | # USE_MODELSCOPE_HUB:使用国内魔搭社区加速模型下载,默认不使用 |
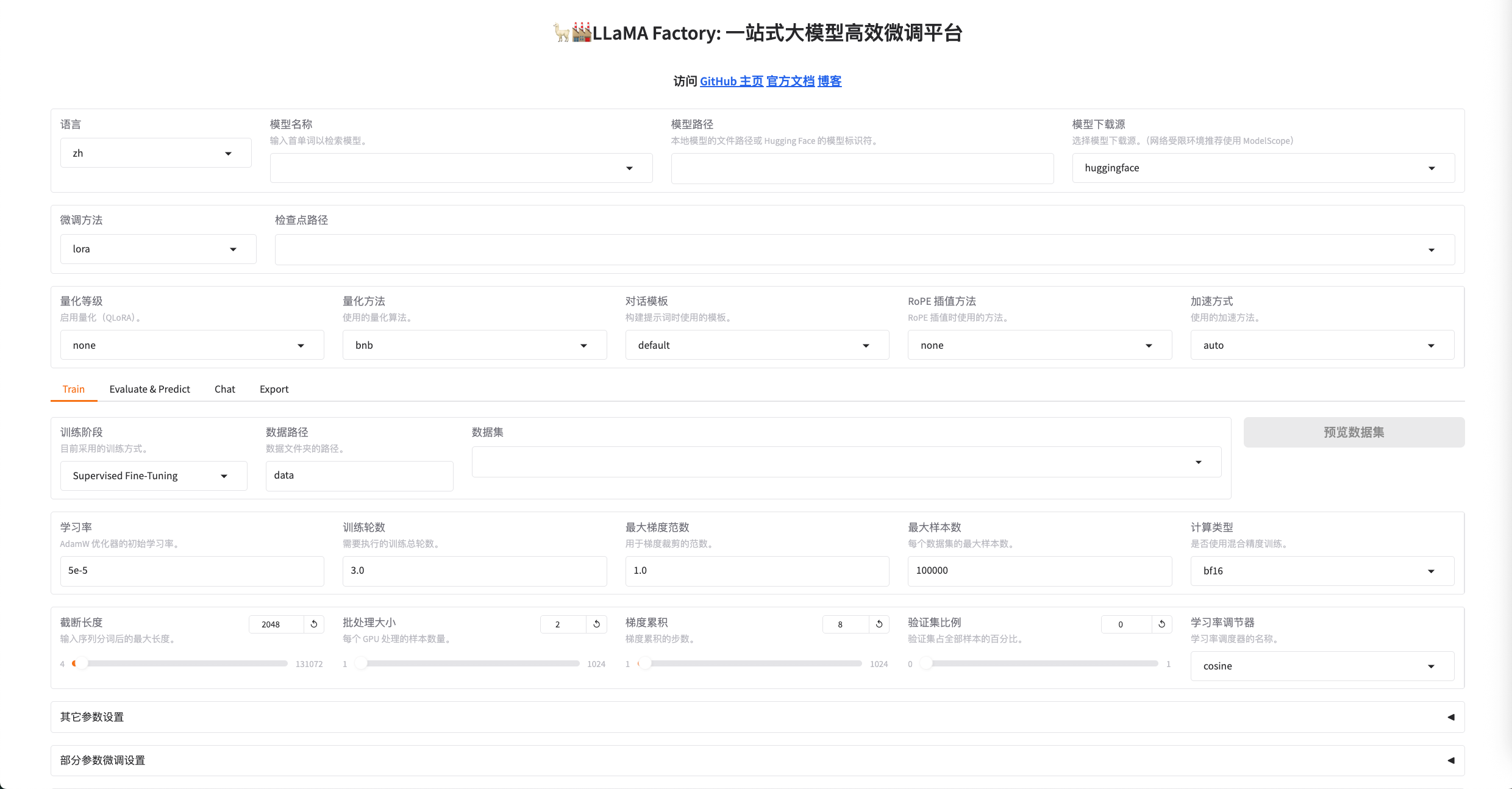
选择模型
选择需要微调的模型 -> Chat -> 加载模型,检查模型是否可用(可以使用本地下载好的模型,或者从公网下载):
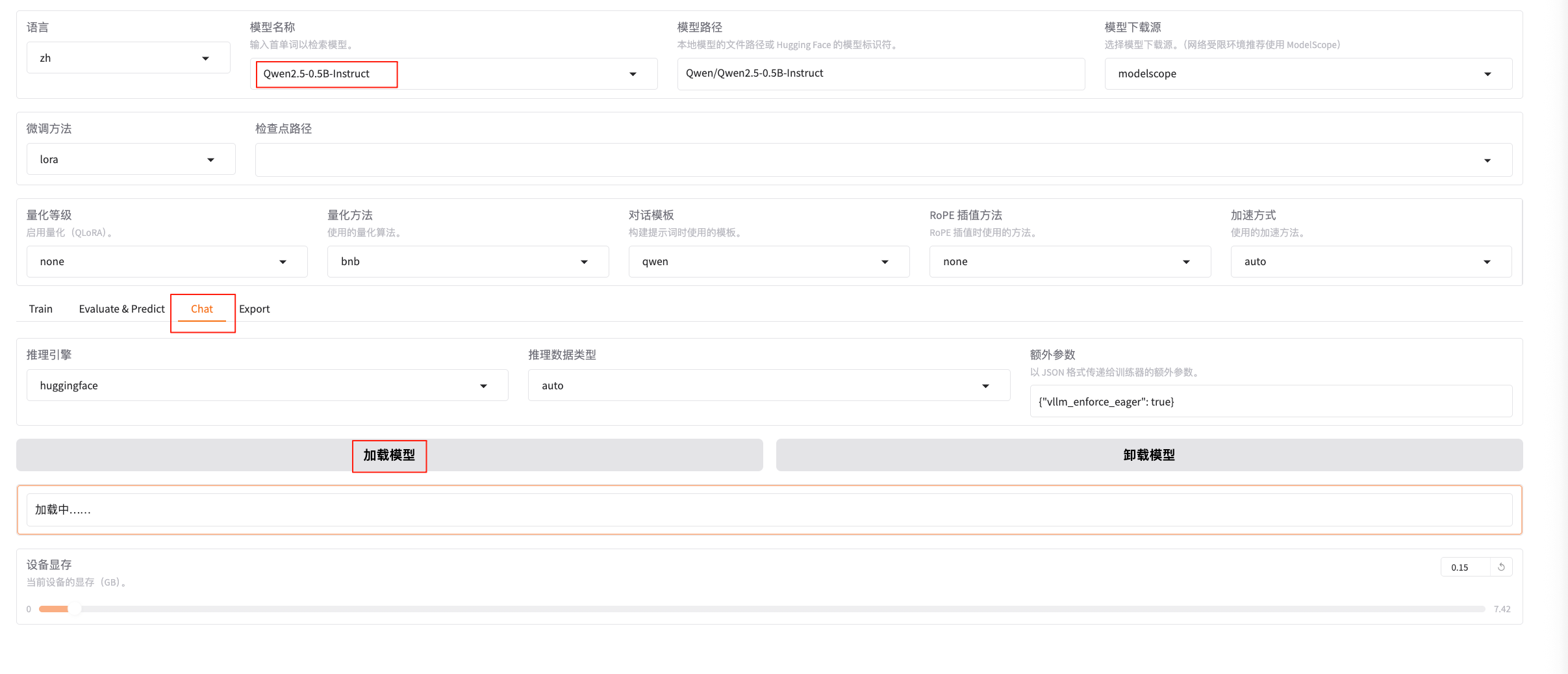
尝试问一个模型无法按预期回答的问题:

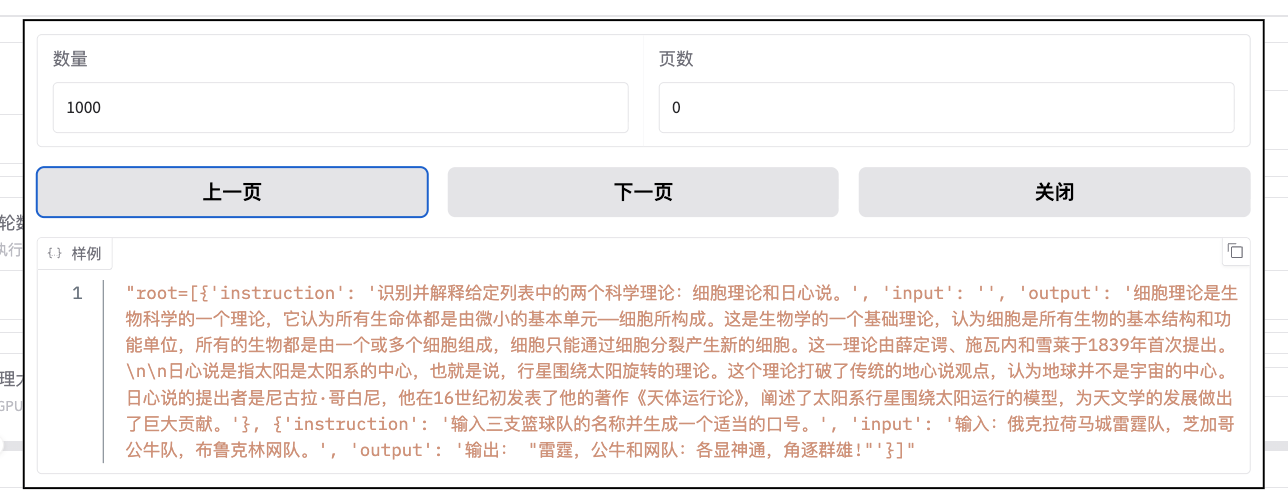
选择数据集
默认情况下容器内的 /app/data 目录下提供部分测试用的数据集,此处选择其中一个进行测试:

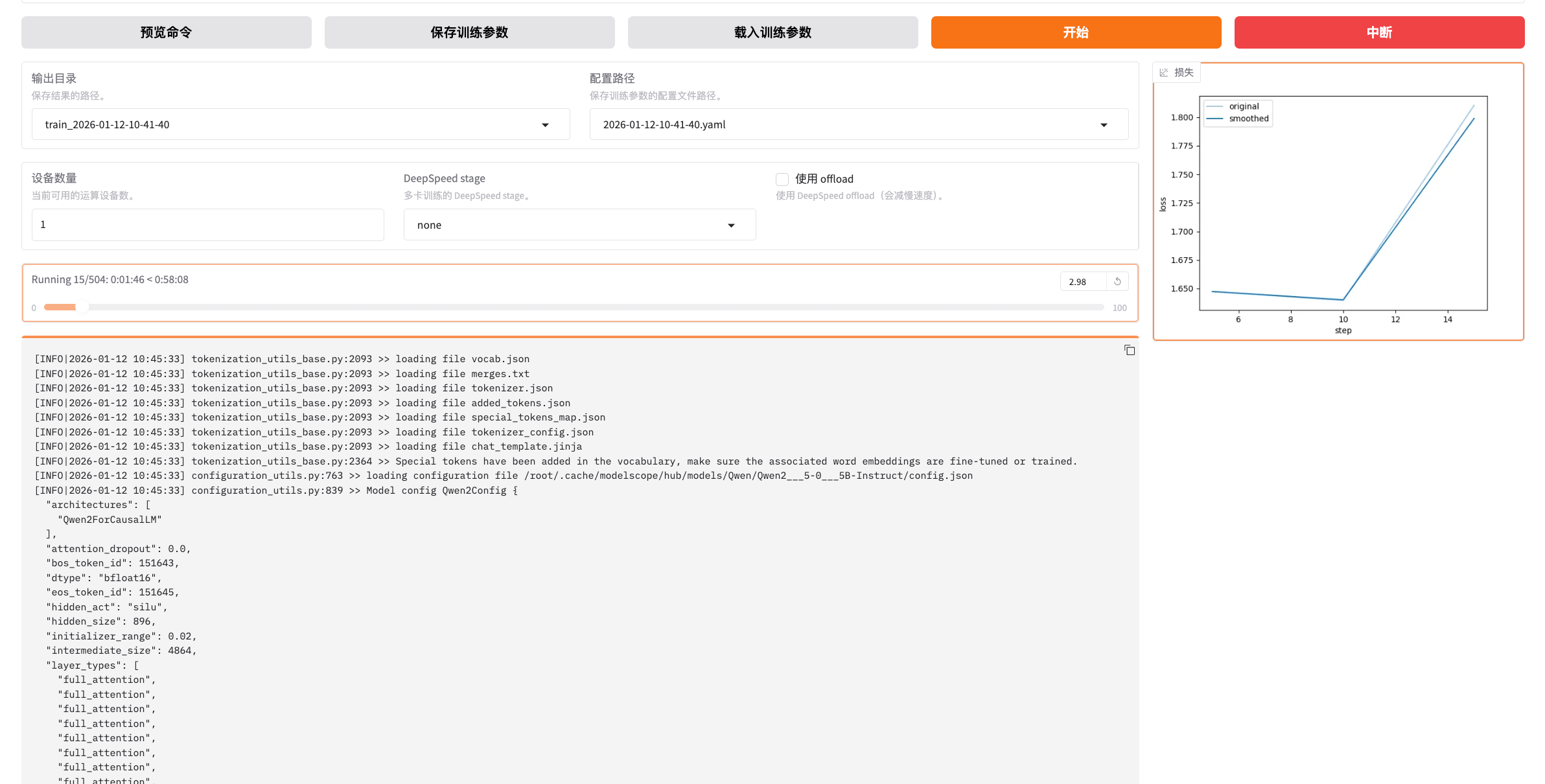
模型微调
为了让模型更好地学习数据知识,进行了以下调整:
- 学习率改为 1e-4,属于偏大的学习率,适合小数据集和让模型明显改变行为
- 训练轮数提高到 8 轮,让模型更容易记住数据集里的数据
- 保存间隔设置为 50,方便回滚对比
- LoRA 秩设置为 16,学习能力适中
- LoRA 缩放系数设置为 32,改动力度偏明显
点击开始进行微调:
等待微调结束后,点击保存训练数据:
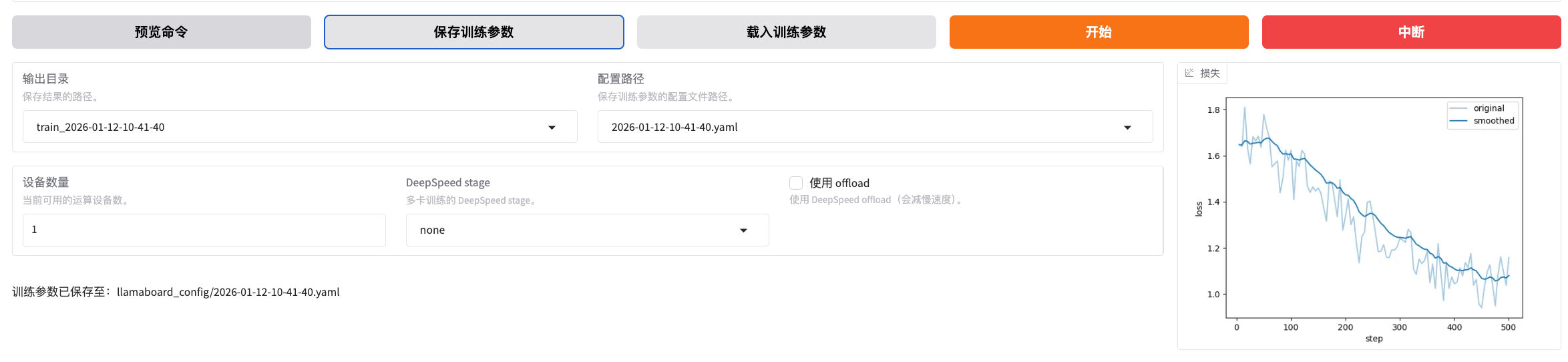
验证微调结果
选择刚刚微调生成的检查点,重新加载模型:
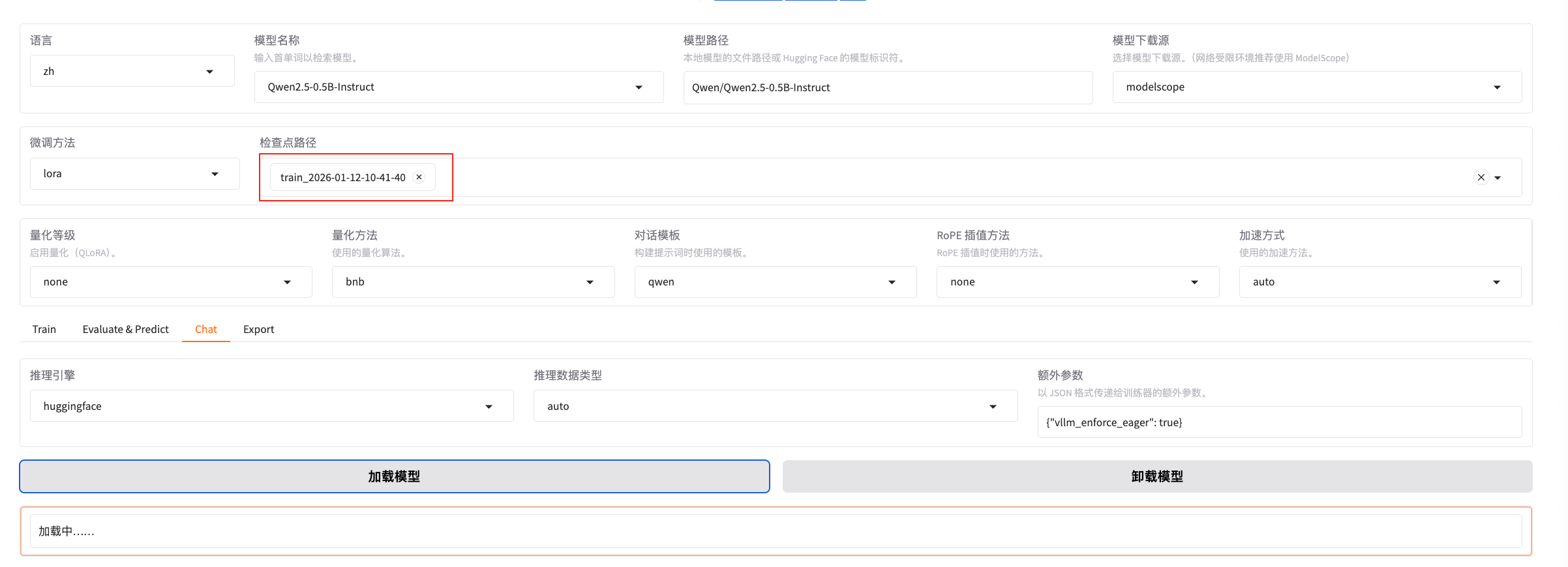
使用同样的问题,再次进行提问:

可以看到回答来自于数据集里的数据:

自定义数据集
如果需要使用自定义的数据集,可以将其存放在 /app/data 目录下,然后在 /app/data/dataset_info.json 填入自定义数据集的信息即可,例如:
1 | "test_dataset": { |
使用 LlamaFactory 进行模型微调
https://warnerchen.github.io/2026/01/12/使用-LlamaFactory-进行模型微调/
install_url to use ShareThis. Please set it in _config.yml.