vLLM 基本原理
vLLM(Virtual Large Language Model)是一种用于高效、大规模运行大语言模型(LLM)的推理框架。它主要由两部分组成:推理服务器(负责接收和调度请求、管理网络流量)和推理引擎(负责高效执行模型计算)。
vLLM 的核心机制是 PagedAttention 算法,通过更高效地管理和复用 GPU 显存,减少内存碎片和不必要的拷贝,从而显著提升推理效率,加快生成式 AI 应用的响应速度。
vLLM 的总体目标是最大化吞吐量(即每秒可处理的 Token 数),以支持在同一套 GPU 资源上同时为大量用户提供稳定、高性能的推理服务。
vLLM 的核心原理主要有:
- KV Cache(缓存 Token,即对话的上下文记忆)
- PagedAttention(核心算法,解决存储碎片)
- Continuous Batching(连续批处理,解决计算空闲)
KV Cache
Transformer 和 Attention
了解 KV Cache 之前,需要先了解一下 Transformer 和 Attention。
Transformer 是一个反复堆叠的模块,用 Attention 建模上下文关系。
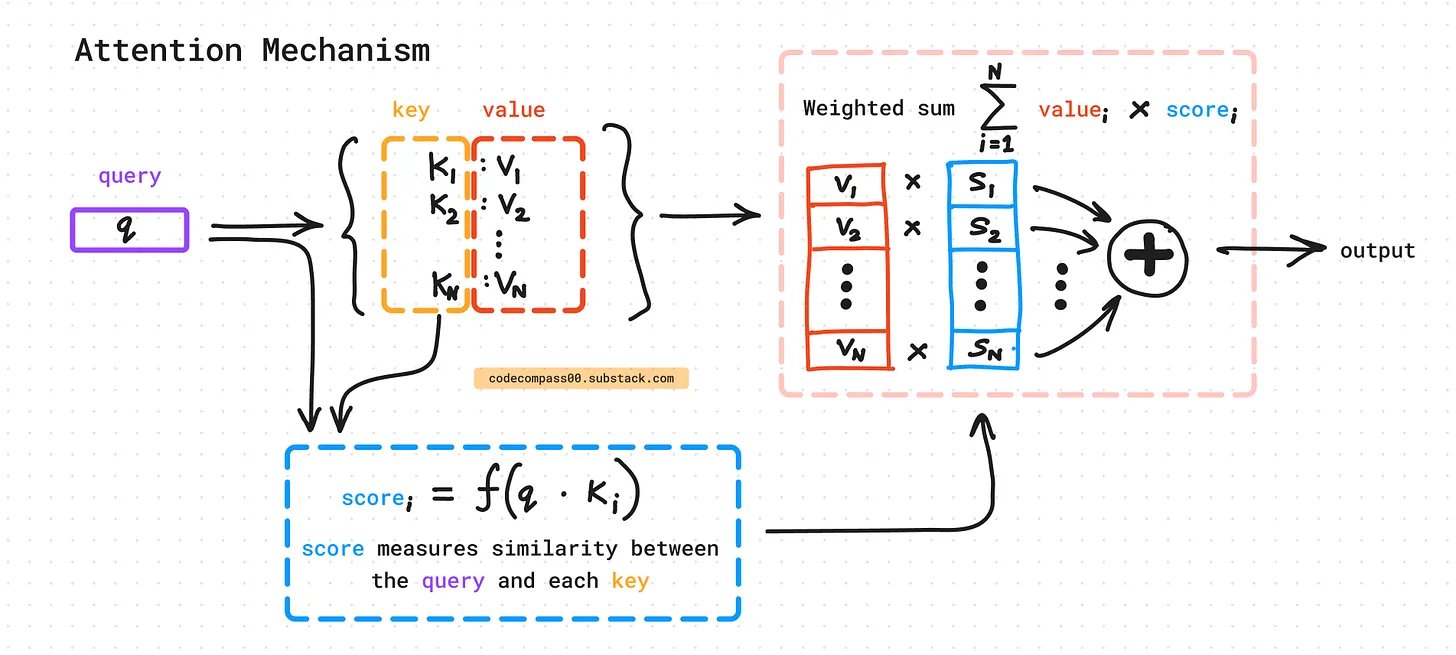
而 Attention 的作用,可以理解为一个加权查询系统:当前 Token 通过 Query,对上下文中所有 Token 的信息进行打分,并加权融合出最相关的表示。
对于每个 Token,模型都会算出:
- Query:我要找什么?
- Key:我是什么?
- Value:我的实际内容是什么?
什么是 KV Cache
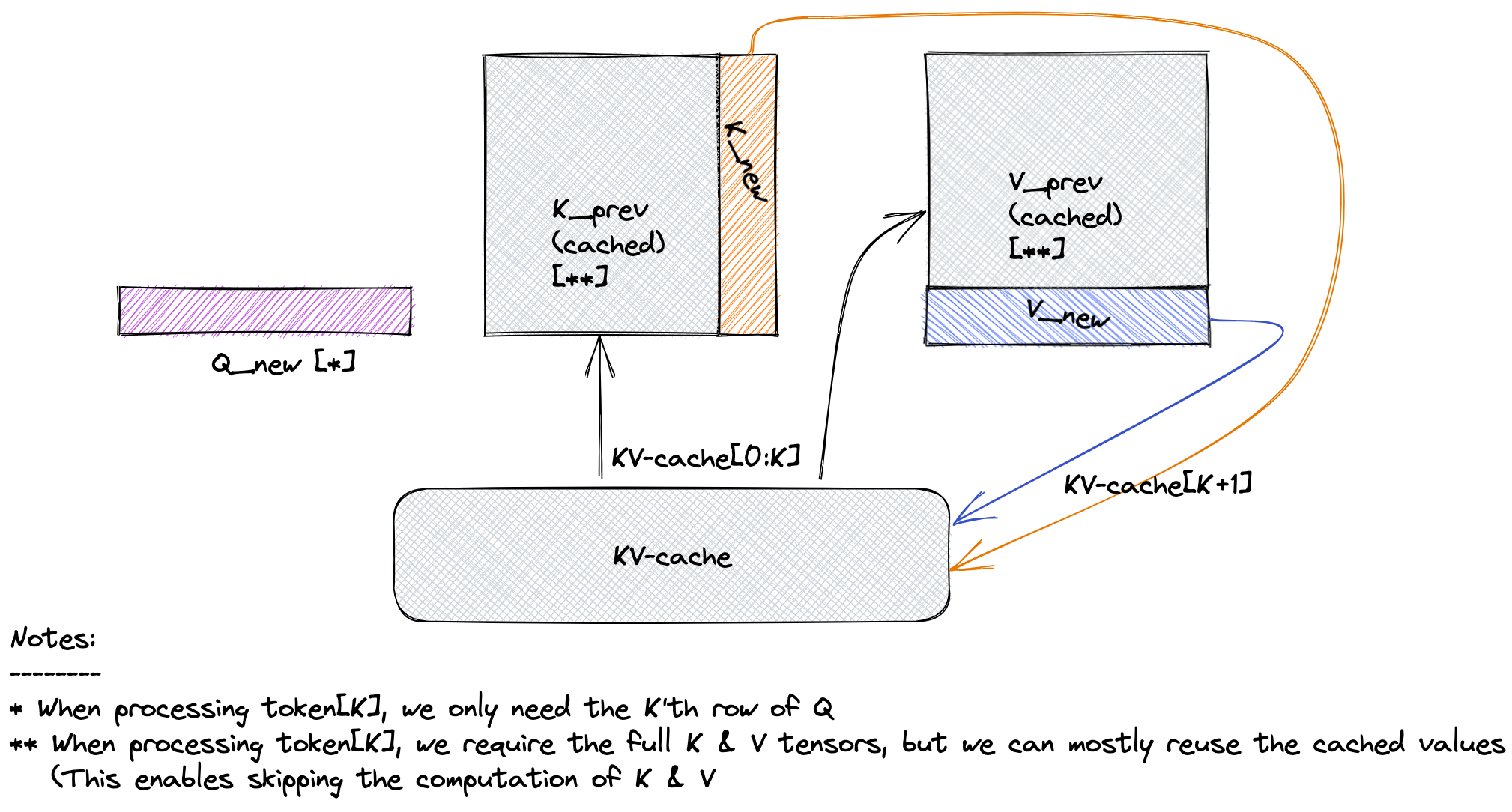
LLM 的文本生成是自回归的:每生成一个新 Token,都需要依赖之前所有 Token 的信息。
如果在生成过程中反复重新计算历史 Token 的 Attention,计算复杂度会迅速上升,效率极低。
因此,模型会将历史 Token 在各层 Attention 中计算得到的 Key 和 Value 向量缓存到显存中,这部分缓存称为 KV Cache。
在生成过程中,KV Cache 会随着序列长度增加而不断累积,从而避免重复计算历史 Token。
KV Cache 的痛点
在传统 LLM 推理(如 HuggingFace Transformers)中,KV Cache 通常按请求独占、连续内存的方式管理。
由于无法预知请求的最终生成长度,系统往往需要按最大上下文长度一次性预分配 KV Cache。
这导致大量显存被提前占用却无法充分利用,同时不同长度请求难以混合调度,显存碎片化后系统吞吐迅速下降。
PagedAttention
什么是 PagedAttention
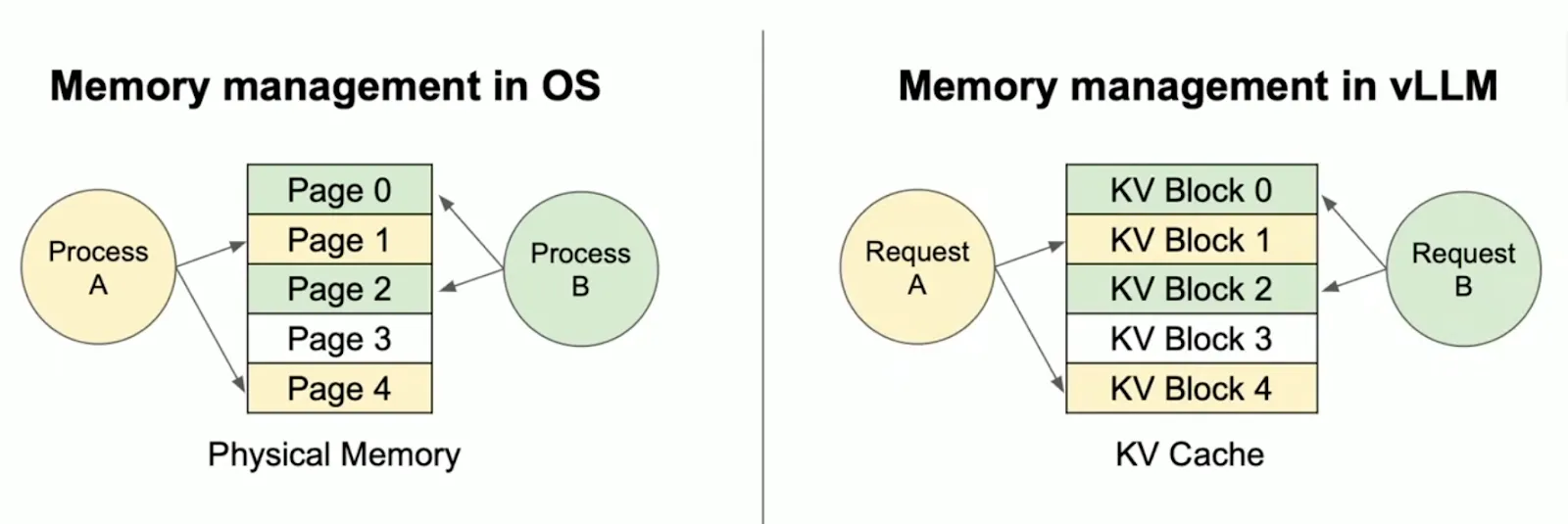
PagedAttention 是 vLLM 的核心算法,它的设计灵感直接来源于操作系统中的虚拟内存(Virtual Memory)和分页(Paging)技术。
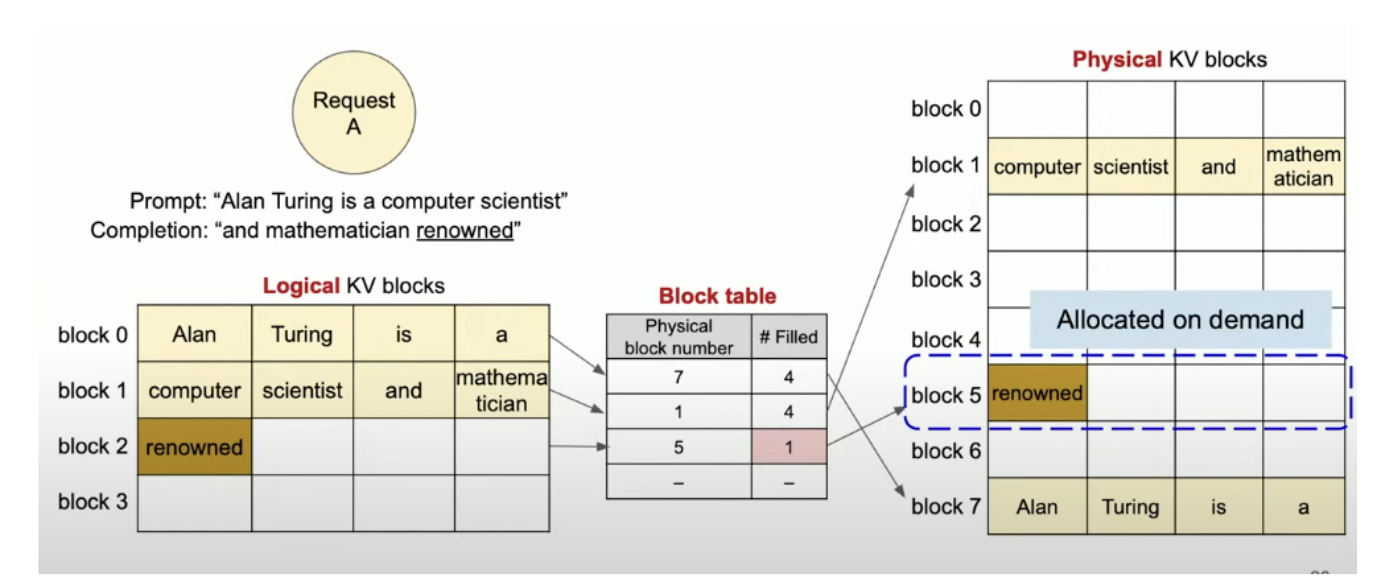
PagedAttention 将 KV Cache 的管理分为三个层级:
- 逻辑块 (Logical Blocks)
- 从 Transformer 的视角看,KV Cache 依然是连续的 Token 序列。
- vLLM 将这个序列切分成固定大小的块(例如
block_size=16)。
- 物理块 (Physical Blocks)
- 从 GPU 显存(VRAM)的视角看,显存被划分为无数个物理块。
- 这些物理块在显存地址空间中可以是非连续的,散落在任何位置。
- 块表 (Block Table)
- 这是核心组件。类似于 OS 的页表(Page Table)。
- 它记录了 逻辑块 ID 物理块 ID 的映射关系。
- 当模型计算 Attention 时,CUDA 内核(Kernel)会根据这张表,去物理显存的各个角落抓取数据进行计算。
PagedAttention 的优点
- 按需分配 (On-Demand Allocation)
- 与传统预分配最大长度不同,PagedAttention 采用动态扩容。
- 当一个 Block 填满数据后,系统才向显存池申请下一个新的物理 Block。
- 好处是消除了内部碎片。除了最后一个 Block 可能没填满,其他 Block 都是 100% 利用率。
- 非连续存储 (Non-Contiguous Storage)
- 物理 Block 不需要挨在一起。
- 好处是消除了外部碎片。只要显存池里剩下的总空间够一个 Block 大小,就能被利用起来,不再需要寻找整块连续的大内存。
- 内存共享 (Memory Sharing)
- 让 AI 基于同一个 Prompt 生成 3 个不同的结局时,3 个输出序列在逻辑上是独立的。
- 但在物理上,它们的 Prompt 部分(公共前缀)指向同一个物理 Block。
- 只有当它们生成各自不同的新 Token 时,才会分配新的私有 Block。
- 好处是能够大幅降低复杂任务的显存占用。
Continuous Batching
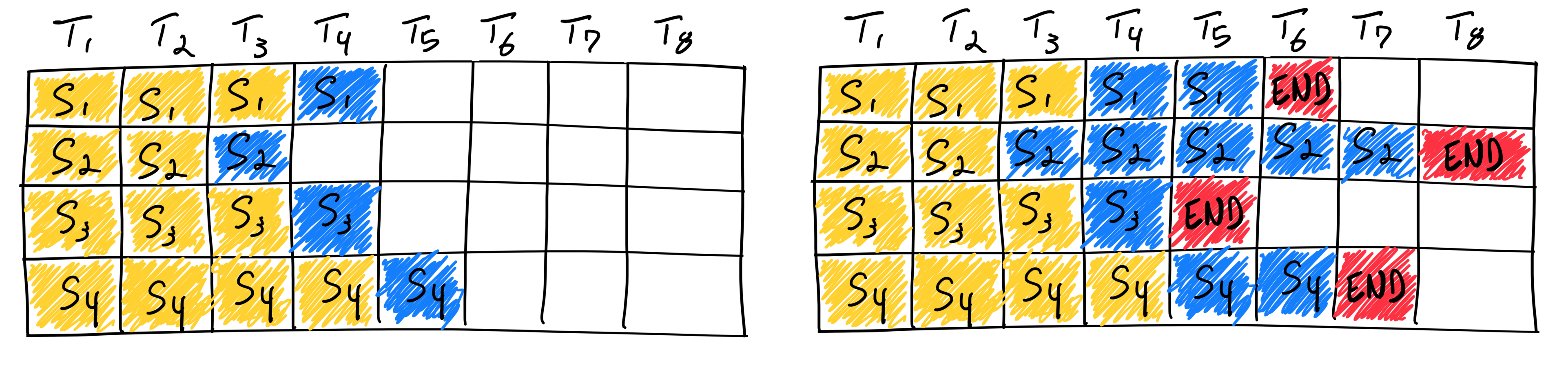
传统 Batching 的痛点
在 vLLM 出现之前,由于显存必须连续分配,推理引擎使用的是 Static Batching(静态批处理)。
举个例子,当前有四个请求:
- Req A:短问题,生成的长度只有 10 个词。
- Req B:长问题,生成的长度有 100 个词。
- Req C / D:中等长度问题,生成的程度有 50 个词。
在 Static Batching 的工作模式下:
- 四个请求会同时处理。
- 由于 Req A 生成长度较短,所以最快完成,但需要等待最长的问题 Req B 也完成后,才能释放资源。
- 也就是说,在 Req A 等等的这段时间,资源仍然被占用,但却不做任何有效计算,造成资源浪费。
Continuous Batching 工作原理
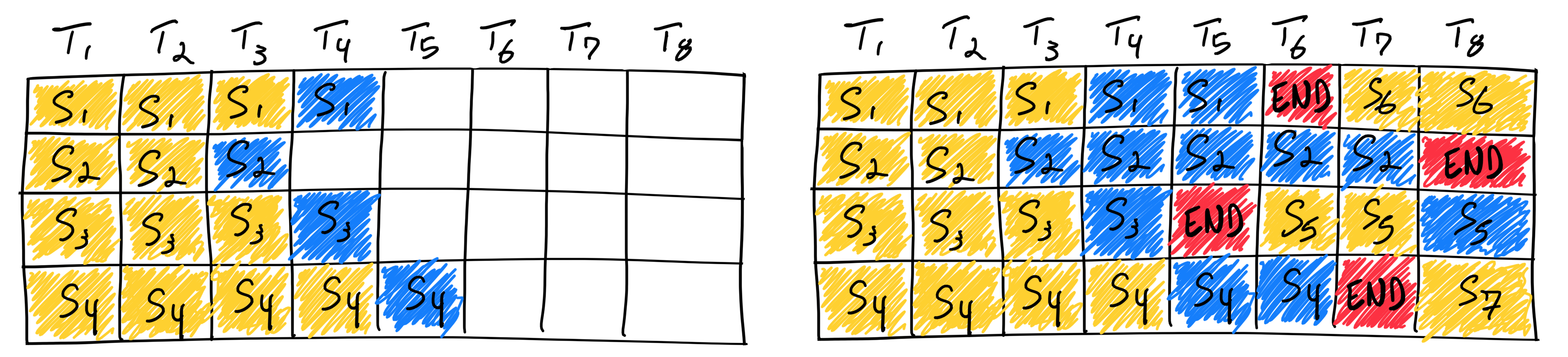
同样的例子,Continuous Batching 的处理方式为:
- 四个请求会同时处理。
- 当 Req A 完成后,会立即释放其占用的资源,给新的请求使用。
Continuous Batching 的工作需要极强的显存管理能力配合。在没有 PagedAttention 之前,Req A 完成后释放的资源,是显存里的一块碎片。如果新来的请求比 Req A 长,根本塞不进去。
只有当显存变成页(Block)式管理后,Req A 释放的 Block 可以立刻分配给新的请求(哪怕该请求的长度需要更多的 Block,也可以先给它几个 Block 跑起来,不够再动态申请),这才实现了真正的 Continuous Batching。
install_url to use ShareThis. Please set it in _config.yml.