使用 Easy DataSet 生成微调数据
Easy Dataset 是一个专为创建大型语言模型(LLM)微调数据集而设计的应用程序。它提供了直观的界面,用于上传特定领域的文件,智能分割内容,生成问题,并为模型微调生成高质量的训练数据。
项目地址:https://github.com/ConardLi/easy-dataset
部署 Easy Dataset
此处使用 Docker 部署:
1 | git clone https://github.com/ConardLi/easy-dataset.git |
修改 docker-compose.yaml 文件,注释数据库相关配置:
1 | ... |
部署 Easy Dataset:
1 | docker compose up -d |
部署大模型
后续数据生成需要调用大模型,此处使用 Ollama 部署大模型:
1 | docker run -d --gpus=all -v /root/ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama |
下载大模型:
1 | # 使用魔塔社区下载大模型:https://modelscope.cn/docs/models/advanced-usage/ollama-integration |
生成微调数据
此处测试使用示例数据:https://github.com/the-seeds/FinancialData-SecondQuarter-2024
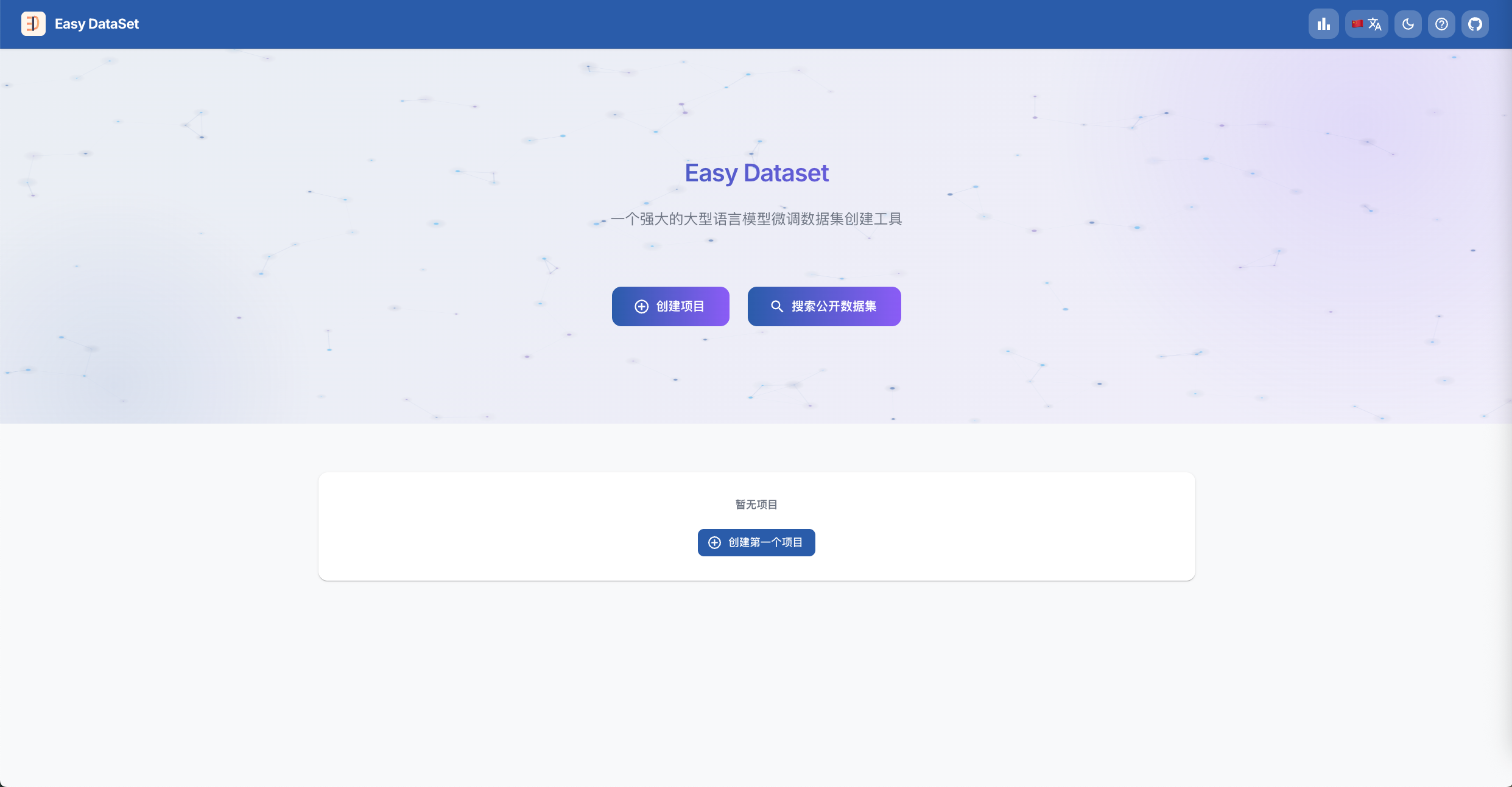
创建项目:
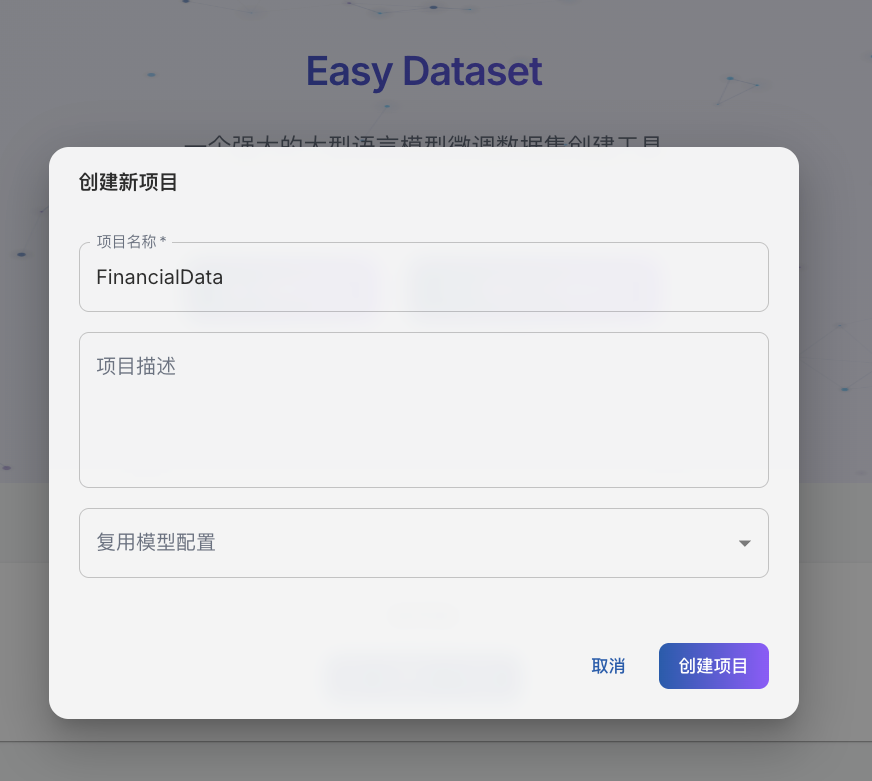
在模型配置界面编辑 Ollama,选择刚刚下载的大模型:
在右上角选择大模型:
在数据源 -> 文献处理,上传示例数据文件:
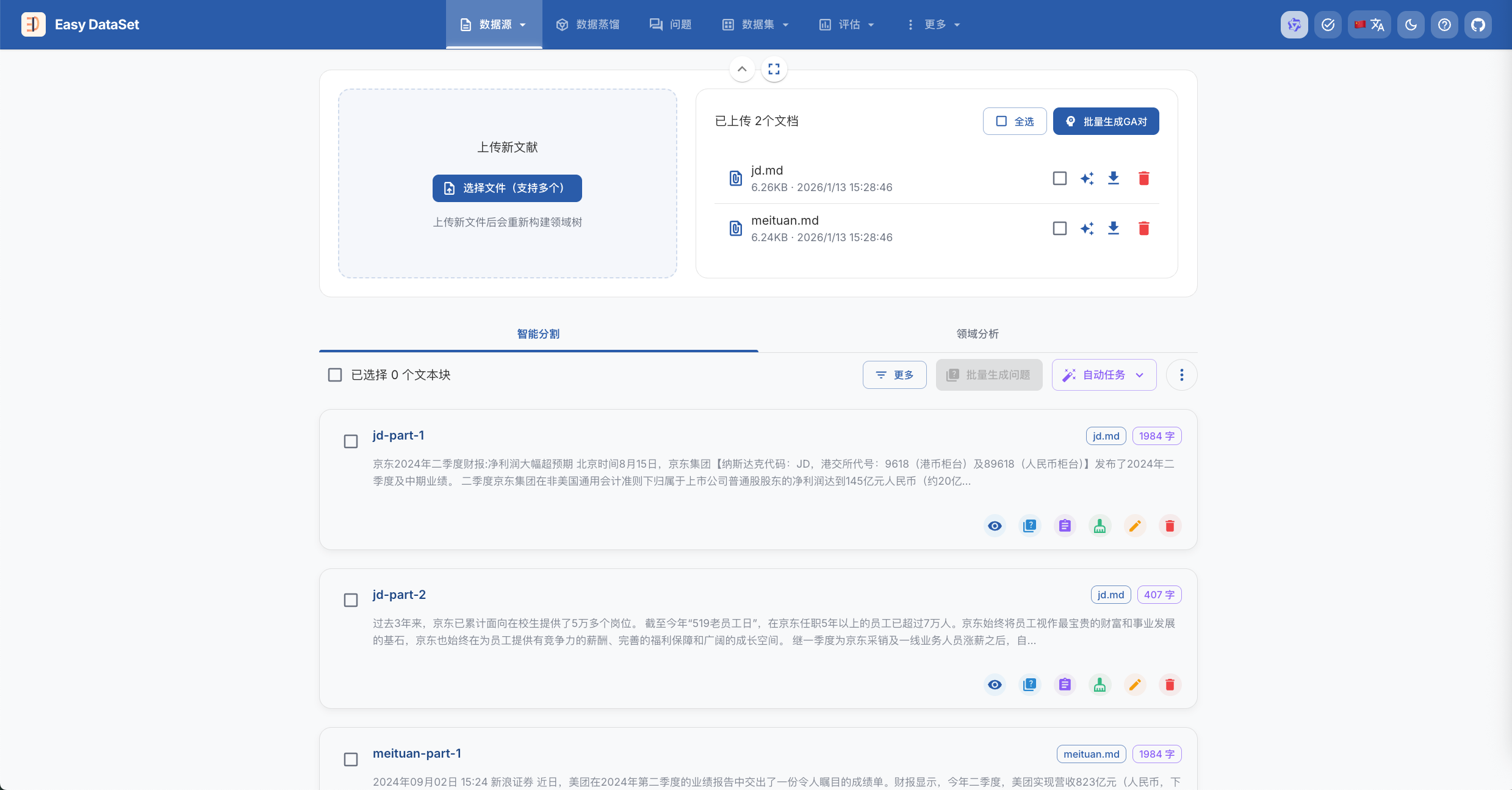
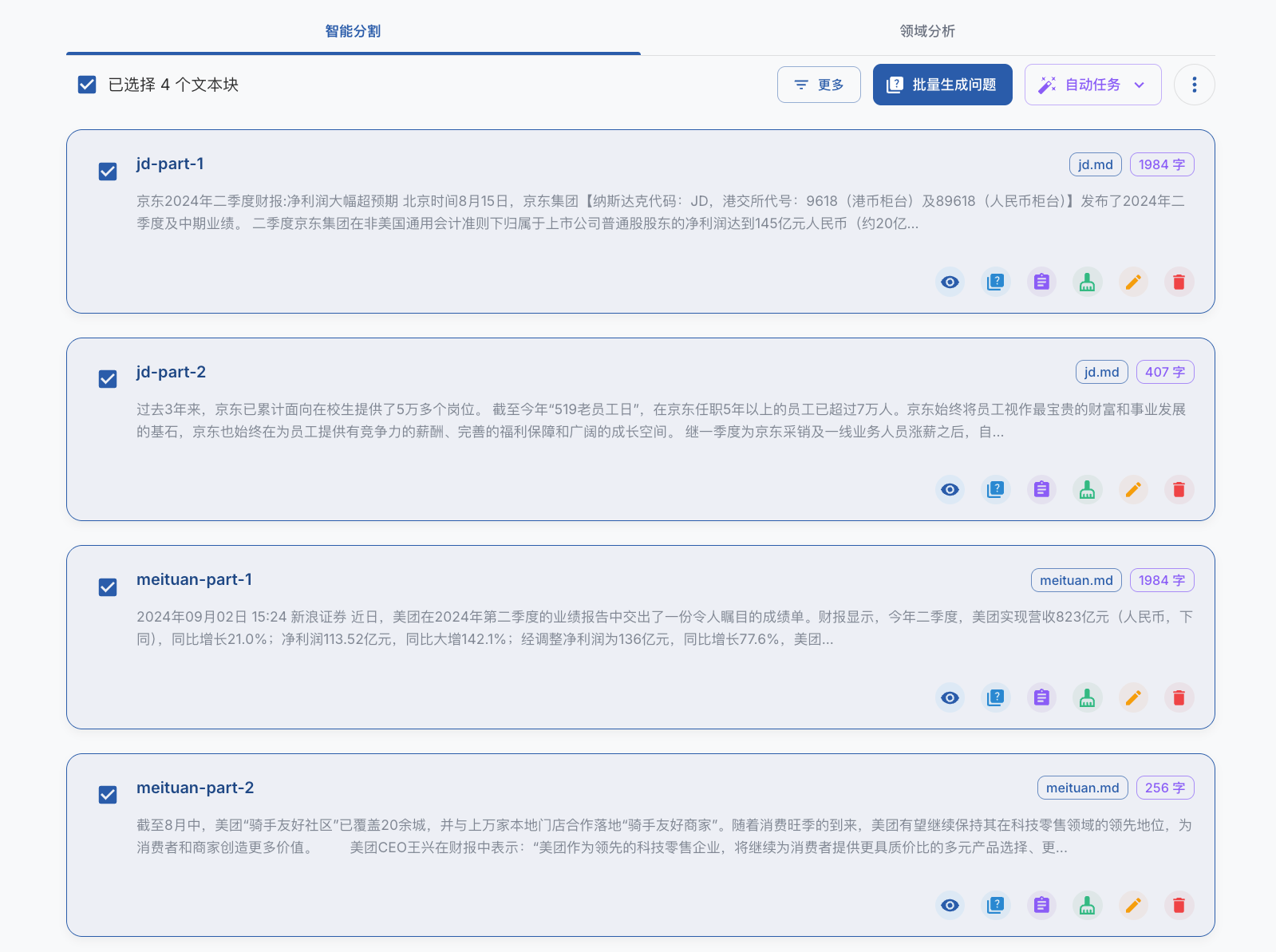
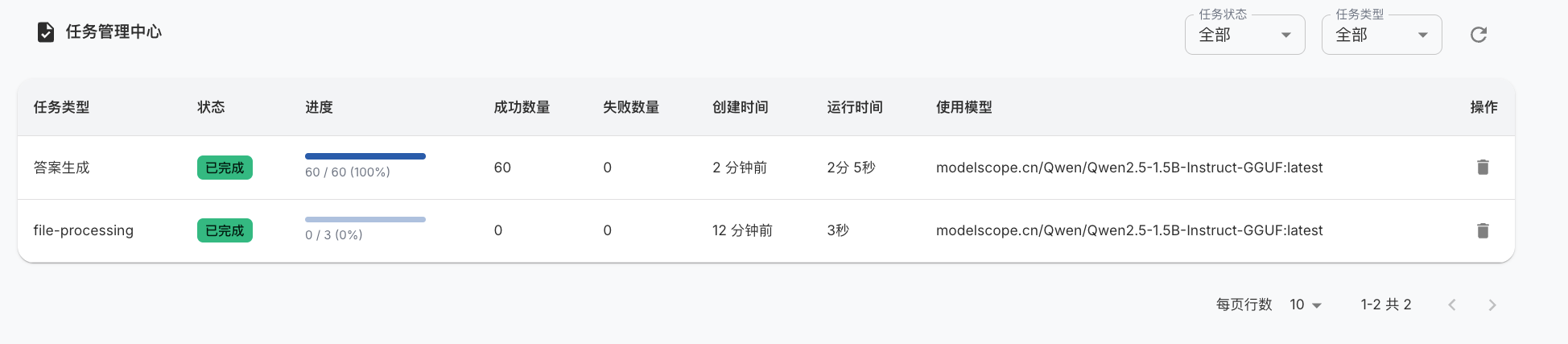
点击批量生成问题:
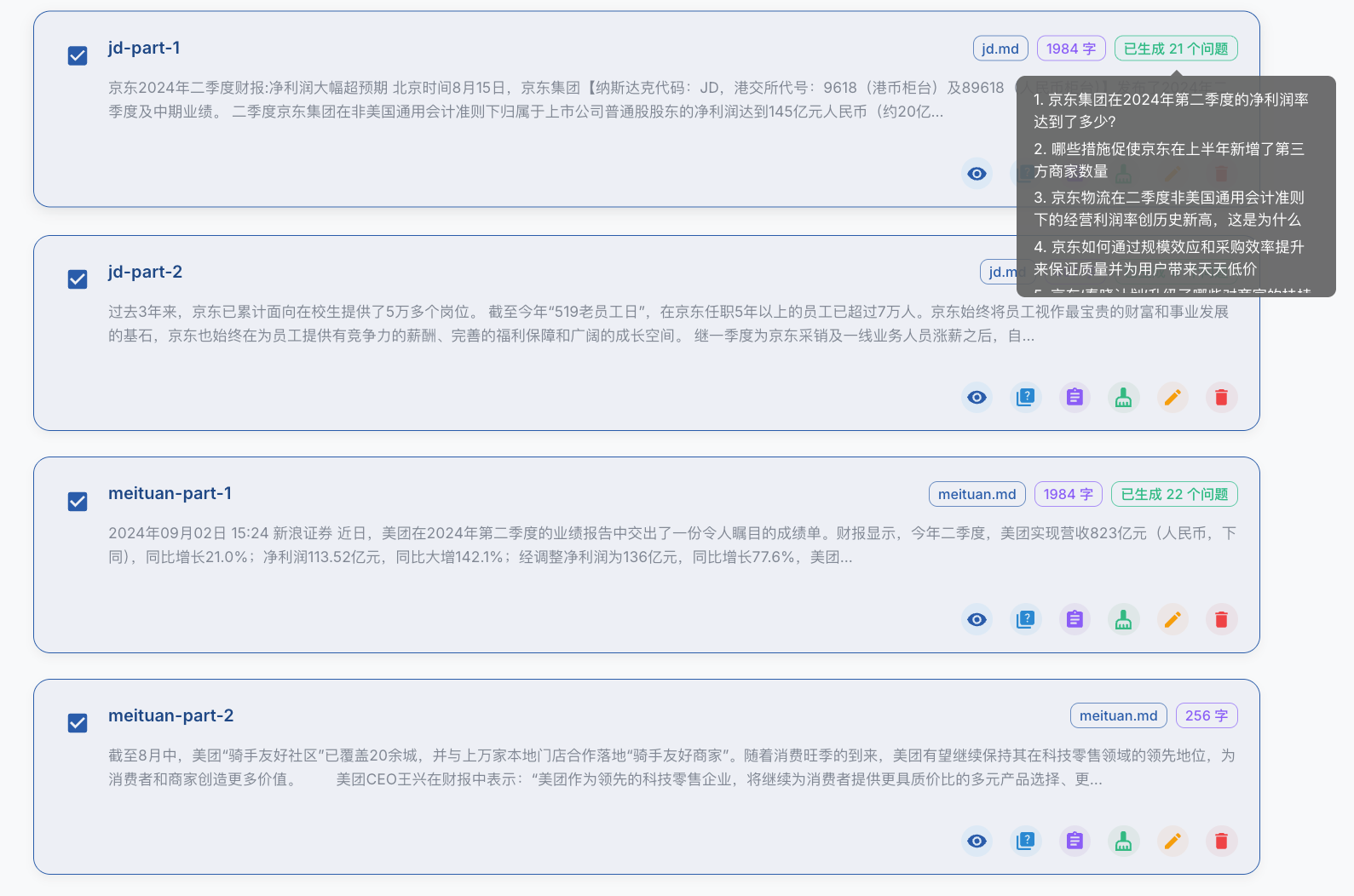
待任务完成后,可以看到生成的问题数据:
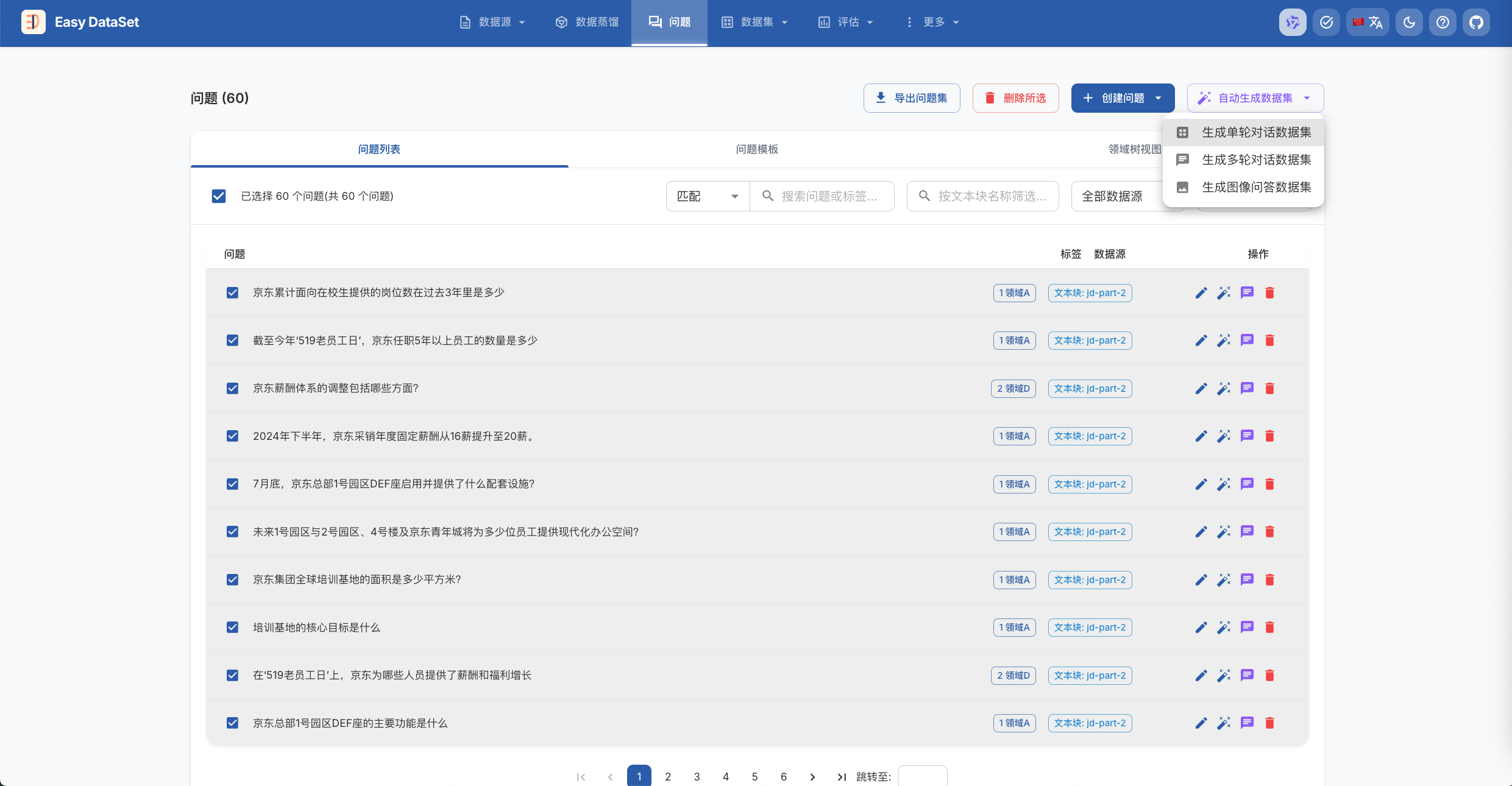
在问题界面,生成数据集:
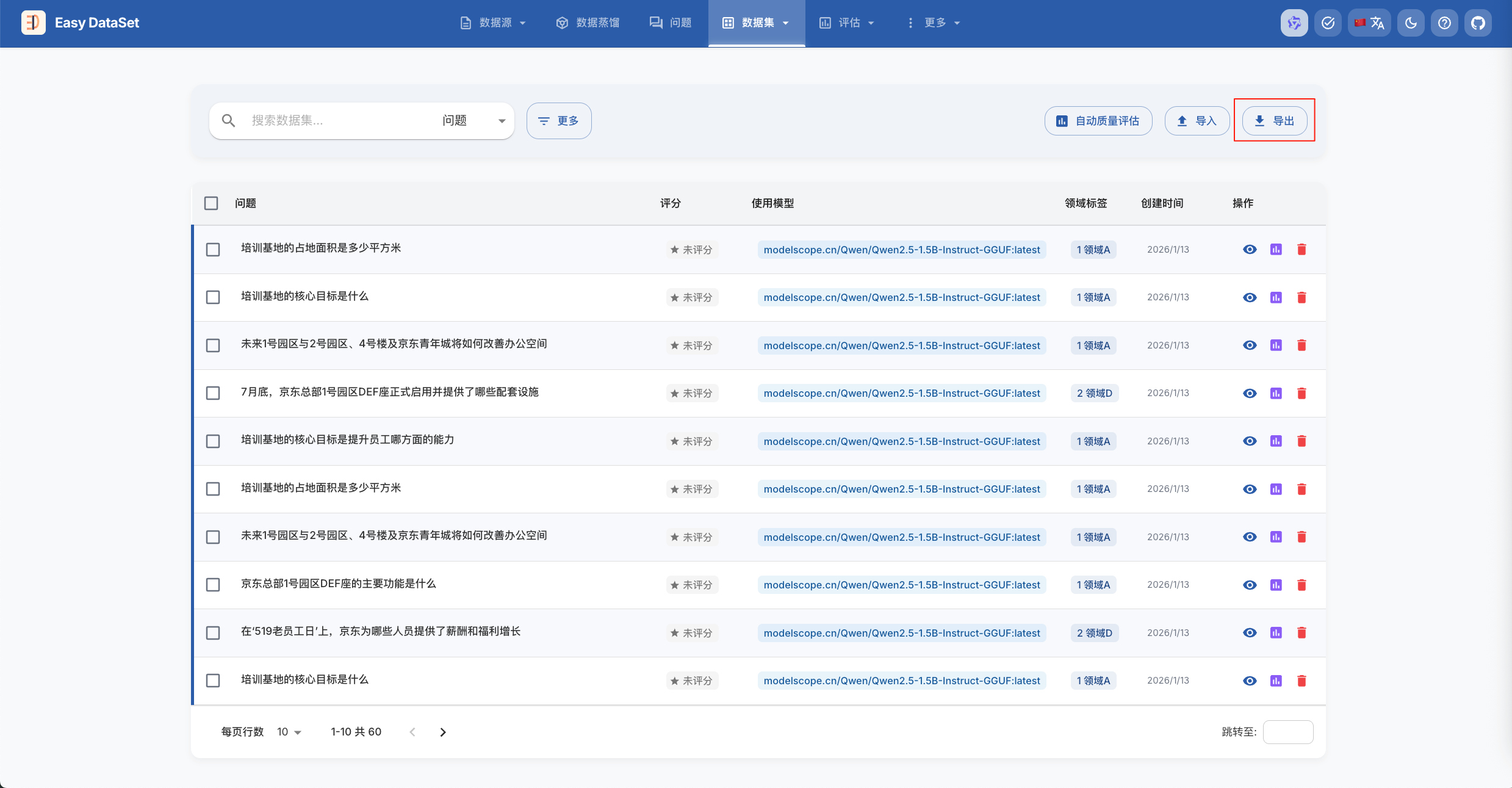
导出微调数据
在数据集界面,导出数据集:
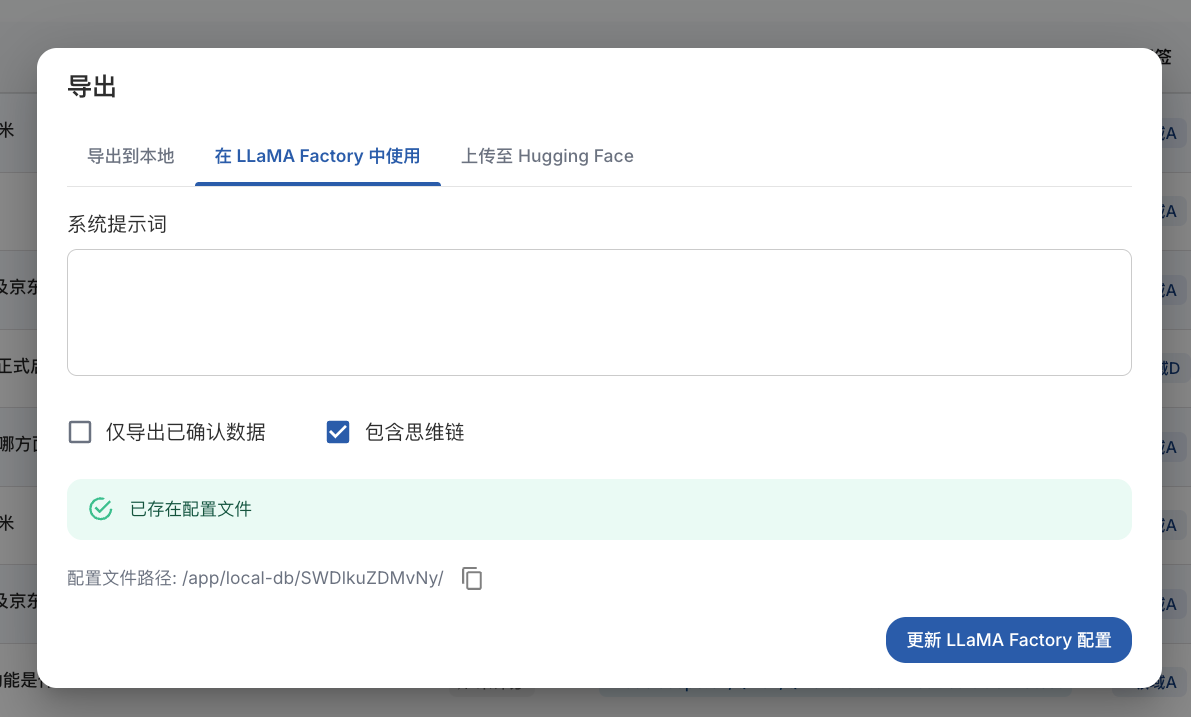
导出后,在数据目录可以找到对应的导出文件:
1 | root@gpu-0:~/easy-dataset/local-db/SWDlkuZDMvNy# ls -lh |
主要关注这三个文件:
- dataset_info.json:LlamaFactory 所需的数据集配置文件
- alpaca.json:以 Alpaca 格式组织的数据集文件
- sharegpt.json:以 Sharegpt 格式组织的数据集文件
将 alpaca.json 和 sharegpt.json 存放在 LlamaFactory 的 /app/data 目录下,并修改 /app/data/dataset_info.json,将导出的 dataset_info.json 内容追加进去即可。
LlamaFactory 使用数据集进行微调
模型微调前:

模型微调后:

使用 Easy DataSet 生成微调数据
https://warnerchen.github.io/2026/01/13/使用-Easy-DataSet-生成微调数据/
You need to set
install_url to use ShareThis. Please set it in _config.yml.