使用 Tailscale 官方的中继节点,很多时候会出现延迟过高的问题(严重的时候基本没法用),如果有云主机,可以用来自建中继。
Read more
使用 Tailscale 官方的中继节点,很多时候会出现延迟过高的问题(严重的时候基本没法用),如果有云主机,可以用来自建中继。
如果希望在不修改原有 DNS 配置的前提下,仅针对特定域名使用指定的 DNS 服务器进行解析,可以参考以下方式实现:
MetalLB 是使用标准路由协议(ARP/BGP)为 Bare Metal Kubernetes 集群实现的负载平衡器。
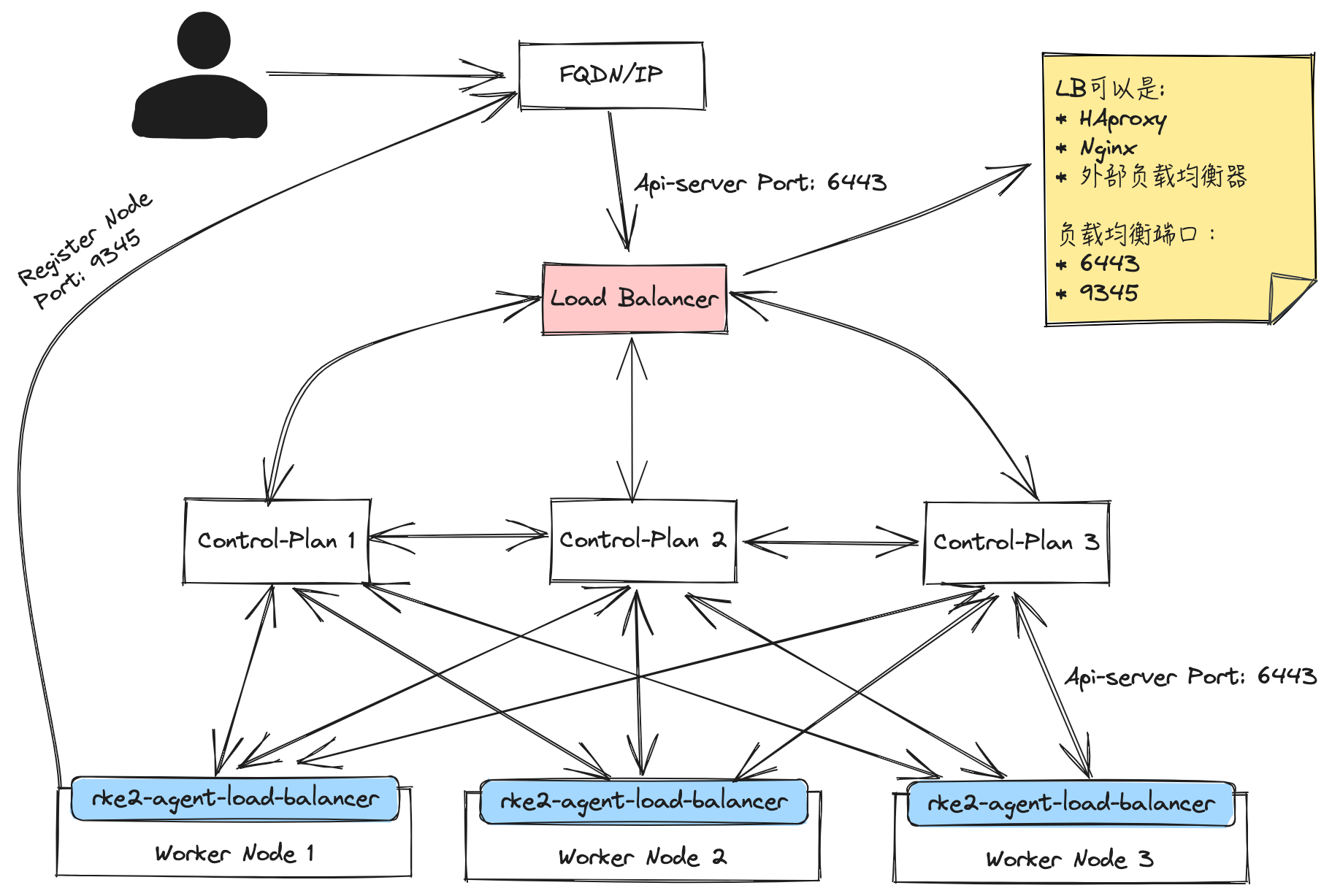
参考文档:https://docs.rke2.io/zh/security/certificates#using-custom-ca-certificates
在注册首台 RKE2 节点时,rke2 进程会检查 /var/lib/rancher/rke2/server/tls 目录中是否已存在相关证书文件;若不存在,就会生成相关证书供 Kubernetes 使用。
如果有自定义证书的需求,也可以提前将生成好的证书放置到该目录中。rke2 会检测到证书已存在,从而跳过证书生成流程,直接使用这些自定义证书。