Rancher Monitoring Grafana 出现 504 错误
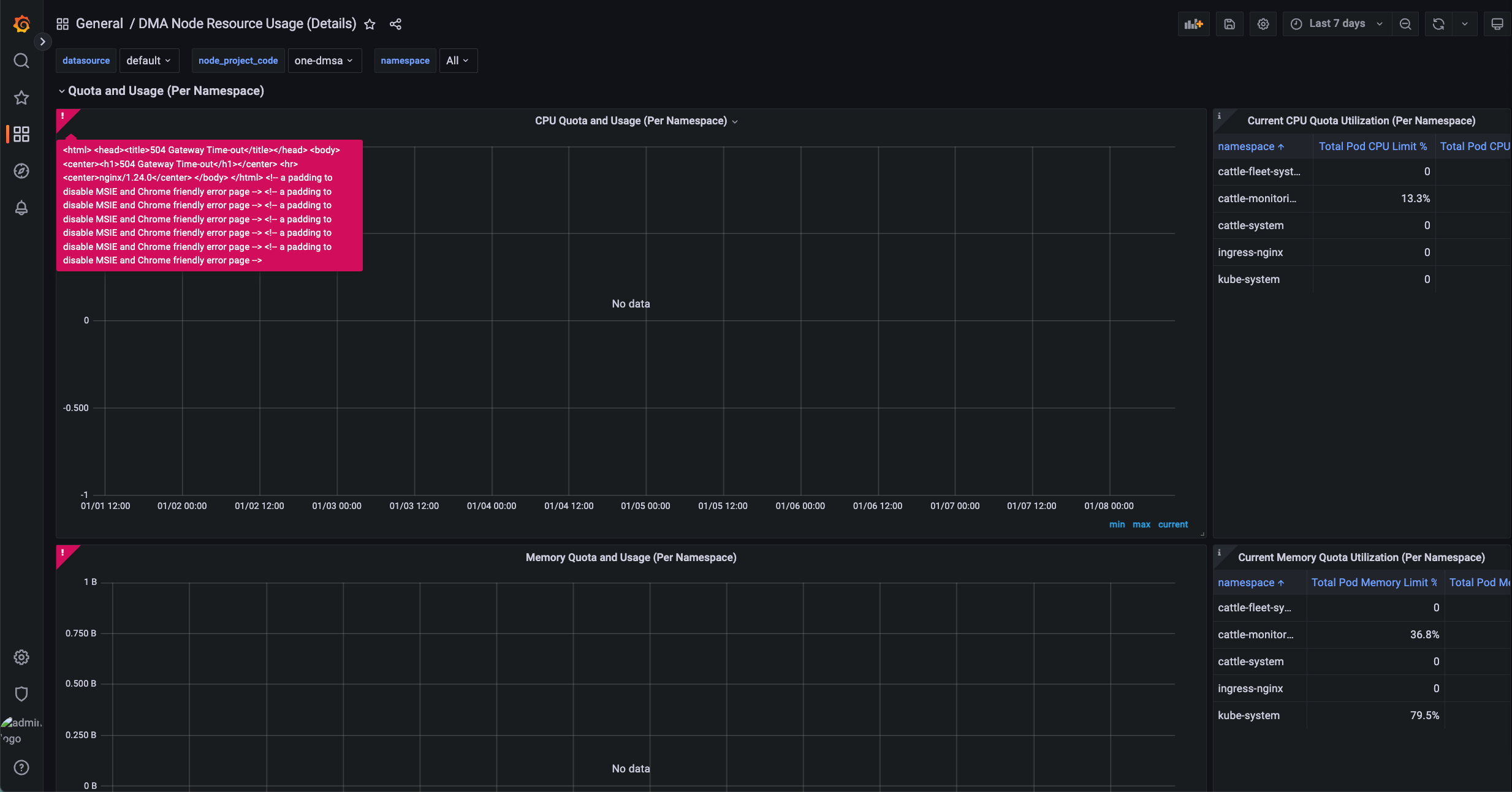
Rancher Monitoring V2 中,Grafana 通过 Nginx 作为反向代理(grafana-proxy)访问 Prometheus。当 Grafana 执行 PromQL 查询且返回数据量较大(例如查询时间范围较长)时,Prometheus 可能无法在 Nginx 的超时时间内完成响应,从而导致 Grafana 返回 504 Gateway Timeout 错误:
Rancher Monitoring Grafana 出现 504 错误
Rancher Monitoring V2 中,Grafana 通过 Nginx 作为反向代理(grafana-proxy)访问 Prometheus。当 Grafana 执行 PromQL 查询且返回数据量较大(例如查询时间范围较长)时,Prometheus 可能无法在 Nginx 的超时时间内完成响应,从而导致 Grafana 返回 504 Gateway Timeout 错误:
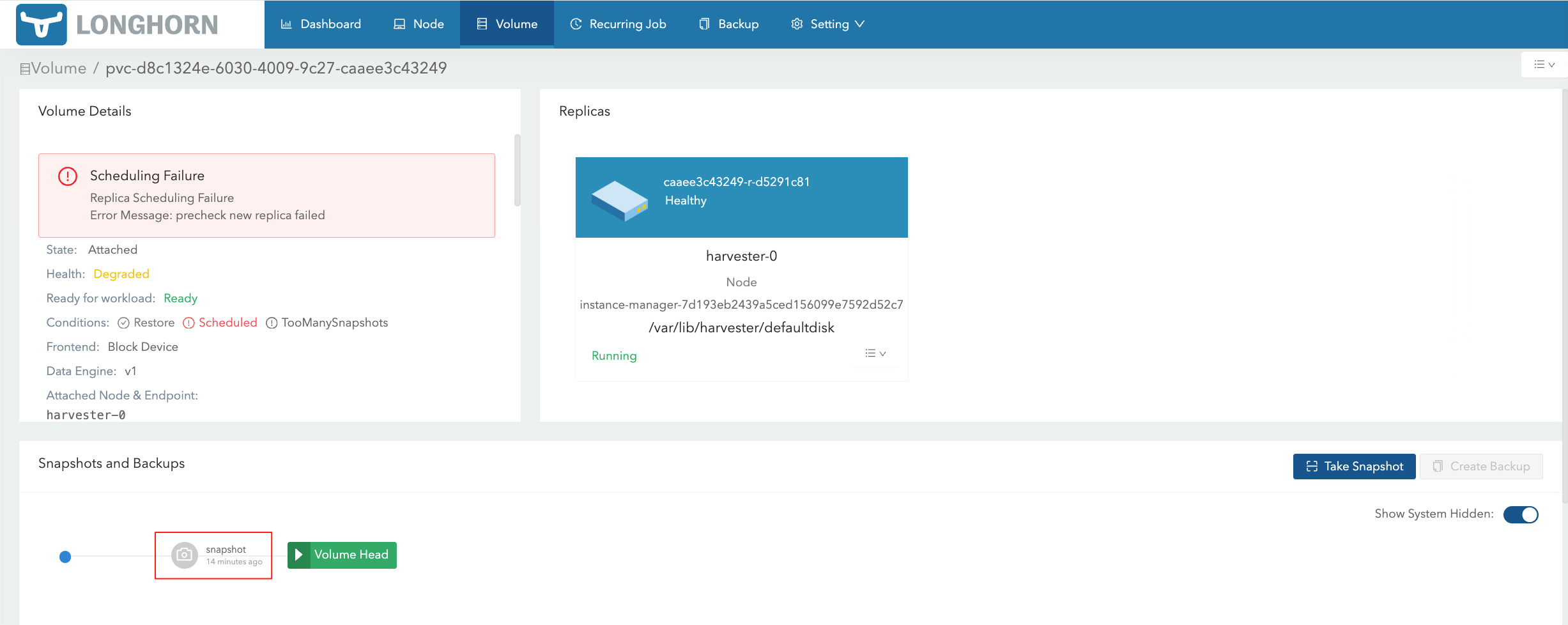
在 HV 将对应的 VM Snapshot 删除后,在 LH 界面仍然能够看到对应的 Volume Snapshot:
Google 的 Firestore Console 无法将 Firestore 数据导出为 CSV/JSON 等格式的文件,经过调研,需要先将 Firestore 数据导出到 GCS,然后再导入 BigQuery 进行格式化,将格式化后的文件导出到 GCS,最后下载到本地。
也可以通过调用 SDK 的方式写代码进行导出。
Harbor 对接 NeuVector Registry Adapter
Harbor 本身支持对存放的制品进行安全扫描,但需要额外部署扫描器。NeuVector 提供了 Registry Adapter 功能,可与 Harbor 对接以实现扫描能力。
如果通过 Rancher UI 误删除了下游 RKE2 集群节点,最简单的恢复方式是重新注册节点;若涉及节点数量较多且需要快速恢复,可通过恢复 local 集群和下游 RKE2 集群的 ETCD 快照来完成恢复。
需要注意的是,仅恢复下游 RKE2 集群的 ETCD 快照是不够的。对于 Custom 类型的 RKE2 集群,每个节点在 local 集群中都对应有 Machine 等资源,因此需要一并考虑恢复。
此方法需要确保 local 集群和下游 RKE2 集群都有删除操作前的 ETCD 快照备份。